

There have been a number of discussions recently around what a next generation architecture should look like for a large-scale infrastructure. As I have discovered over the past few months, there is a stark difference from what current public cloud and private cloud offerings generally have and what Google is doing publicly and publishing in their technical documents. The piece that gets me most excited is the discussion around this, what others see as a solution, including their perspective, and then realizing how close the things I am passionate about align with what is coming next.
So along those lines, and after reading a few different white papers, I came to the conclusion that the current form of BDE could be used as a foundation for offering up a piece of the next-generation architecture in a PaaS focused infrastructure. The solution itself is rather simplistic and BDE yields itself very easily to accomplishing the end-goal of offering up a pure HDFS layer for enterprise data.
HortonWorks has an excellent image depicting the type of solution I, and others, are envisioning. Once you have the base layer presenting the data through HDFS, there are a variety of services/applications that can then be utilized in upper-layers of the platform stack to consume said data.
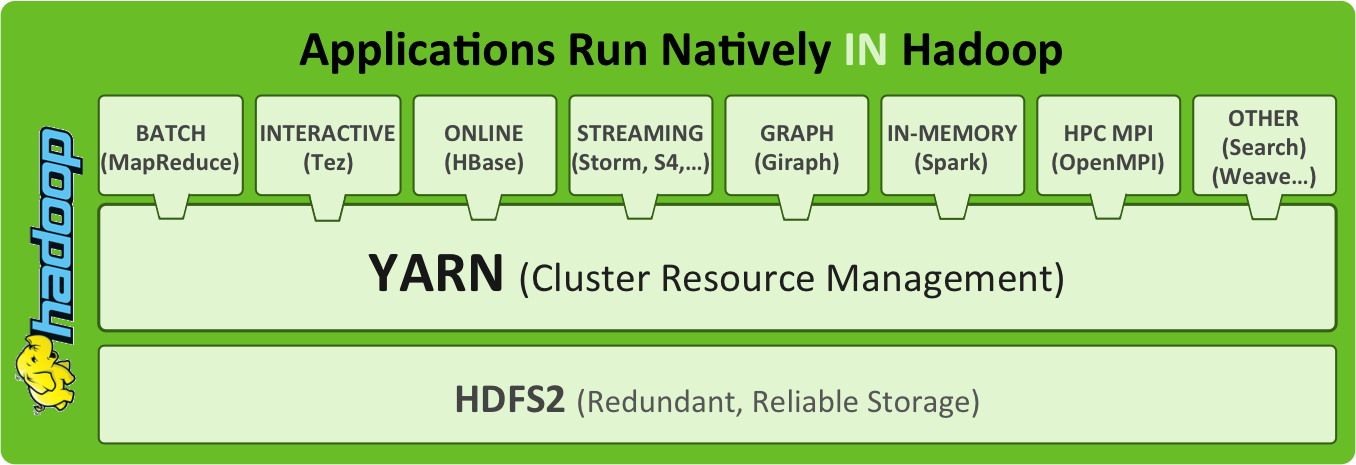
The example shows YARN being used for the cluster resource manager, but even then you are not specifically tied down. You could use another resource manager, like Apache Mesos, to handle that role. That is part of flexibility of building this type of infrastructure from the ground up — based on the needs of the platform, you can use the tools that best fit the requirements.
First thing you have to realize is the pieces are already there within BDE. The Big Data Extensions already allow a person to deploy a compute-only cluster and point it to an HDFS cluster. What we are talking about here is just doing the exact opposite and it all starts with a new cluster definition file. A good working example can be found in the whitepaper “Scaling the Deployment of Multiple Hadoop Workloads on a Virtualized Infrastructure.”
By virtualizing the HDFS nodes within your rack-mount servers with DAS, you can customize how each node appears within the cluster. The cluster is then capable of taking advantage of using the Hadoop Virtulized Extensions (whitepaper) to ensure data locality within the physical nodes. At which point you have a pure HDFS layer that can be presented to any number of cluster resource managers, be they physical, virtual or a combination of the two. The flexibility gained from having this sort of layer quickly adds benefit to the PaaS offerings.
Building out HDFS using this set of technologies is a great first step towards building a next-generation cluster level PaaS offering. I will keep you updated as hardware and performance testing determines the architecture design.



