

There is a quote in the book “Hadoop Operations by Eric Sammer (O’Reilly)” where it states:
“The complexity of sizing a cluster comes from knowing — or more commonly, not knowing — the specifics of such a workload: its CPU, memory, storage, disk I/O, or frequency of execution requirements. Worse, it’s common to see a single cluster support many diverse types of jobs with conflicting resource requirements.”
In my experience that is a factual statement. It does not however, preclude one from determining that very information so that an intelligent decision can be made. In fact, VMware vCenter Operations Manager becomes an invaluable tool in the toolbox when developing the ability to maintain the entire SDLC of a Hadoop cluster.
Initial sizing of the Hadoop cluster in the Engineering|Pre-Production|Chaos environment of your business will include some amount of guessing. You can stick with the tried and true methodology of answering the following two questions — “How much data do I have for HDFS initially?” and “How much data do I need to ingest into HDFS daily|monthly?” It is at this point that you’ll need to start monitoring the workload(s) placed on the Hadoop cluster and begin making determinations for the cluster size once it moves into the QE, Staging and Production environments.
VMware vCenter Operations Manager (vCOPs) helps a VMware administrator to understand the individual workloads on a granular level from the individual VM all the way up to the ‘world’ view. Tying vCOPs into all of the different environments is key and will give you the greatest visibility into managing your Hadoop-as-a-Service infrastructure to provide a high-quality service level.
Start working with your Engineering teams early in the SDLC to understand the workload they will be generating on an individual cluster. Once the team has ingested data into HDFS and begun writing their MapReduce jobs, show them some of the vital metrics gathered through vCOPs to understand their workload.
Here are a couple of examples of metrics and dashboard items within vCOPs that should be of some assistance.

Here you can see statistics at a VMware cluster level. In this particular case, there is a 128-node Hadoop compute-only cluster that is running with an Isilon-backed HDFS layer. This is a broad overview of the single cluster running, but we can quickly see that vCOPs is telling us the cluster is memory bound.
The next screenshot shows a bit more information as it looks at a few specific metrics for the cluster to help us understand the workload better.
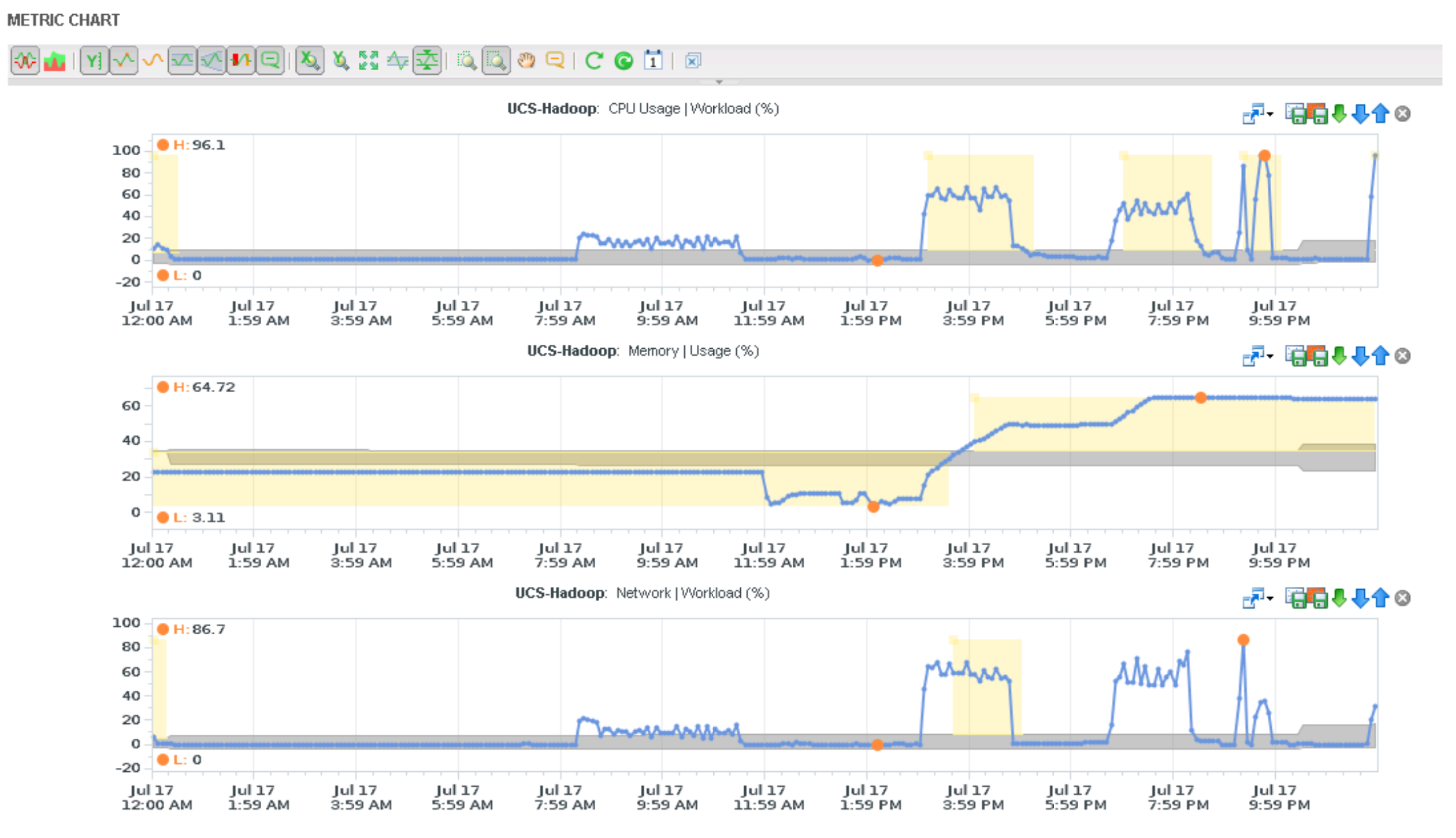
The interesting piece here are we look at the three main resources for our compute-only cluster — CPU, Memory and Network — is that we can see that the memory across the cluster is peaking at about 65% utilization.
From here you can begin to make determinations about how many nodes the cluster should include, the size of the compute nodes, the size of the data nodes, etc.
The key point I want to make is that you need to work with your Engineering teams early on in the SDLC to help both you and them to understand the workload they will be generating. From there vCOPs can — and should — become an integral part of the environment to prove or disprove assumptions made about the Hadoop clusters.
No single answer exists here. Recognizing that what you discover with one cluster may not be applicable to the next. What is important is the flexibility your Hadoop-as-a-Service platform can offer your organization when it is virtualized.



