

After working with EMC over the summer and evaluating the capabilities of utilizing Isilon storage as an HDFS layer, including the NameNode, it got me thinking about how the VMware Big Data Extensions could be utilized to create the exact same functionality. If you’ve read any of the other posts around extending the capabilities of BDE beyond just what it ships with, you’ll know the framework allows an administrator to do nearly anything they can imagine.
As with creating a Zookeeper-only cluster, all of the functionality for a HDFS-only cluster is already built into BDE — it is just a matter of unlocking it. It took less than 10 minutes to set up all the pieces.
I needed to add Cloudera 5.2.1 support into my new BDE 2.1 lab environment, so the first command sets that functionality up. After that, the rest of commands are all that are needed:
# config-distro.rb --name cdh5 --vendor CDH --version 5.2.1 --repos http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/cloudera-cdh5.repo
# cd /opt/serengeti/www/specs/Ironfan/hadoop2/ # mkdir -p donly # cp conly/spec.json donly/spec.json # vim donly/spec.json
I configured the donly/spec.json file to include the following:
1 {
2 "nodeGroups":[
3 {
4 "name": "DataMaster",
5 "description": "It is the VM running the Hadoop NameNode service. It manages HDFS data and assigns tasks to workers. The number of VM can only be one. User can specify size of VM.",
6 "roles": [
7 "hadoop_namenode"
8 ],
9 "groupType": "master",
10 "instanceNum": "[1,1,1]",
11 "instanceType": "[MEDIUM,SMALL,LARGE,EXTRA_LARGE]",
12 "cpuNum": "[2,1,64]",
13 "memCapacityMB": "[7500,3748,max]",
14 "storage": {
15 "type": "[SHARED,LOCAL]",
16 "sizeGB": "[50,10,max]"
17 },
18 "haFlag": "on"
19 },
20 {
21 "name": "DataWorker",
22 "description": "They are VMs running the Hadoop DataNode services. They store HDFS data. User can specify number and size of VMs in this group.",
23 "roles": [
24 "hadoop_datanode"
25 ],
26 "instanceType": "[SMALL,MEDIUM,LARGE,EXTRA_LARGE]",
27 "groupType": "worker",
28 "instanceNum": "[3,1,max]",
29 "cpuNum": "[1,1,64]",
30 "memCapacityMB": "[3748,3748,max]",
31 "storage": {
32 "type": "[LOCAL,SHARED]",
33 "sizeGB": "[100,20,max]"
34 },
35 "haFlag": "off"
36 }
37 ]
38 }
The final part is to add an entry for a HDFS-Only cluster in the /opt/serengeti/www/specs/map file:
128 {
129 "vendor" : "CDH",
130 "version" : "^\\w+(\\.\\w+)*",
131 "type" : "HDFS Only Cluster",
132 "appManager" : "Default",
133 "path" : "Ironfan/hadoop2/donly/spec.json"
134 },
Restart the Tomcat service on the management server and the option is now available. The configured cluster when it is done looked like this in the VMware vCenter Web Client:
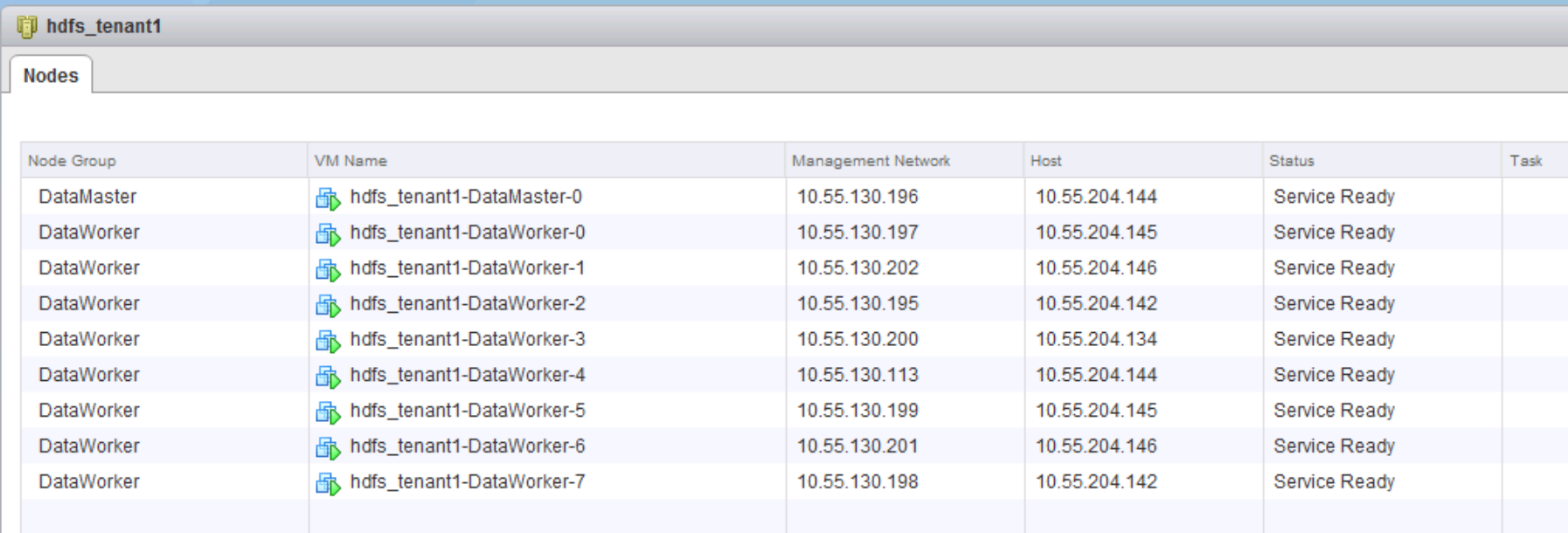
You can view the status of the HDFS layer through the standard interface:

Being able to have this functionality within VMware Big Data Extensions allows an environment to provide a dedicated HDFS data warehouse layer to your applications and other application cells.



