

![]()
Apache Cassandra support has been one of the additional clustered software projects I have wanted to add into the vSphere Big Data Extensions framework. In an effort to build out a robust and diverse service catalog for our private cloud environment, adding Cassandra is one more service we can make available to our customers (which is currently in production use).
For those who are unaware of Apache Cassandra, it is a distributed database management system and the Apache Cassandra Project website states that it is:
“…the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. Cassandra’s support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.”
Below you will find the tutorial for how to implement Apache Cassandra, with the associated JSON files, Chef cookbooks and Chef roles in vSphere Big Data Extensions. All of the files I will be going over are available in GitHub here.
For what is becoming the norm here at Virtual Elephant, adding an additional offering to the framework all starts with the JSON definition file (/opt/serengeti/www/specs/Ironfan/cassandra/spec.json):
1 {
2 "nodeGroups":[
3 {
4 "name": "Seed",
5 "description": "The Apache Cassandra Seed nodes",
6 "roles": [
7 "cassandra_seed"
8 ],
9 "groupType": "master",
10 "instanceNum": "[2,1,2]",
11 "instanceType": "[MEDIUM,SMALL,LARGE,EXTRA_LARGE]",
12 "cpuNum": "[1,1,64]",
13 "memCapacityMB": "[7500,3748,max]",
14 "storage": {
15 "type": "[SHARED,LOCAL]",
16 "sizeGB": "[1,1,min]"
17 },
18 "haFlag": "on"
19 },
20 {
21 "name": "Worker",
22 "description": "The Apache Cassandra non-seed nodes",
23 "roles": [
24 "cassandra_node"
25 ],
26 "instanceType": "[MEDIUM,SMALL,LARGE,EXTRA_LARGE]",
27 "groupType": "worker",
28 "instanceNum": "[3,1,max]",
29 "cpuNum": "[1,1,64]",
30 "memCapacityMB": "[7500,3748,max]",
31 "storage": {
32 "type": "[SHARED,LOCAL]",
33 "sizeGB": "[1,1,min]"
34 },
35 "haFlag": "off"
36 }
37 ]
38 }
Followed up by the new /opt/serengeti/www/distros/manifest entry:
76 {
77 "name": "cassandra",
78 "vendor": "APACHE",
79 "version": "0.0.1",
80 "packages": [
81 {
82 "roles": [
83 "zookeeper",
84 "cassandra_seed",
85 "cassandra_node"
86 ],
87 "package_repos": [
88 "https://hadoop-mgmt.localdomain/yum/bigtop.repo"
89 ]
90 }
91 ]
92 },
As soon as I had the basic cluster definition created, the Chef recipes had to be created in the /opt/serengeti/chef/cookbooks/cassandra directory. The primary recipe (default.rb) has the following code in it:
1 #
2 # Cookbook Name:: cassandra
3 # Recipe:: default
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 include_recipe "java::sun"
18 include_recipe "hadoop_common::pre_run"
19 include_recipe "hadoop_common::mount_disks"
20 include_recipe "hadoop_cluster::update_attributes"
21
22 # Setup the repo file for installing Cassandra
23 template '/etc/yum.repos.d/datastax.repo' do
24 source 'datastax.repo.erb'
25 action :create
26 end
27
28 %w{dsc21 cassandra21-tools}.each do |pkg|
29 package pkg do
30 action :install
31 end
32 end
33
34 execute 'Setup Cassandra Service' do
35 command 'chkconfig cassandra on'
36 end
37
38 all_seeds_ip = cassandra_seeds_ip
39 all_nodes_ip = cassandra_nodes_ip
40
41 template '/etc/cassandra/conf/cassandra.yaml' do
42 source 'cassandra.yaml.erb'
43 action :create
44 variables(
45 seeds_list: all_seeds_ip,
46 cluster_value: node[:cluster_name]
47 )
48 action :create
49 end
50
51 template '/etc/cassandra/default.conf/cassandra-env.sh' do
52 source 'cassandra-env.sh.erb'
53 action :create
54 end
55
56 clear_bootstrap_action
From there it was a matter of creating the recipes for the Seed and Non-Seed nodes within the cluster. Fortunately, the bulk of the configuration and setup happens in the default.rb recipe. As you have seen in my other posts, there are Chef roles that need to be created to match the definitions for the node types within the JSON file. In this case, I created two roles: one for Seeds and one for Non-Seeds.
cassandra_seed:
1 {
2 "name": "cassandra_seed",
3 "description": "",
4 "json_class": "Chef::Role",
5 "default_attributes": {
6 },
7 "override_attributes": {
8 },
9 "chef_type": "role",
10 "run_list": [
11 "recipe[cassandra]",
12 "recipe[cassandra::seed]"
13 ],
14 "env_run_lists": {
15 }
16 }
cassandra_node:
1 {
2 "name": "cassandra_node",
3 "description": "",
4 "json_class": "Chef::Role",
5 "default_attributes": {
6 },
7 "override_attributes": {
8 },
9 "chef_type": "role",
10 "run_list": [
11 "recipe[cassandra]",
12 "recipe[cassandra::node]"
13 ],
14 "env_run_lists": {
15 }
16 }
There are a couple templates that are necessary for the recipes and the cluster configuration to be setup properly. Those can be found, along with all of the files necessary for adding Cassandra to the vSphere Big Data Extensions framework, in the Virtual Elephant GitHub area.
Commit all of your changes to the BDE management server with the ‘knife cookbook upload -a‘ command and restart the Tomcat server to finalize the new capability. Deployment of the cluster should only take a few minutes, depending on your environment, adding another great service catalog item to your vSphere Big Data Extensions and vSphere environment!
Once you have a cluster deployed, you can check the status of the cluster with the command ‘nodetool status‘ on one of the Seed nodes. Here is an example from a cluster I have deployed:
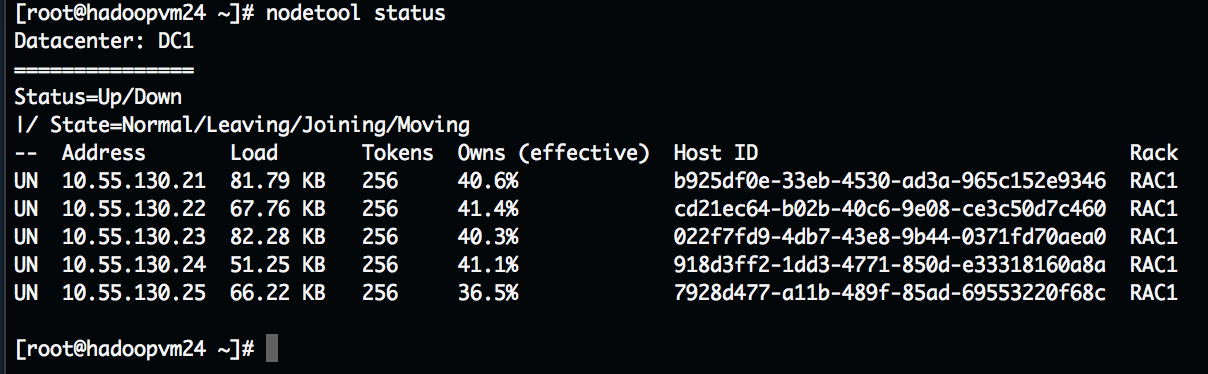
Now you have a running Cassandra cluster for use within your environment and a new capability for your service catalog!
There are several additional applications I am will be adding over the coming weeks, so please keep checking the site for updates. As always, if you have questions or want to talk about any of the work I have done, please reach out to me over Twitter (@chrismutchler).
Enjoy!



