

Apache Mesos was initially created in order to support multiple frameworks within a single cluster. As I have used Mesos over the past six months it has worked amazing for segmenting multiple frameworks from one another, while consolidating the CPU and memory resources provided to the cluster into a single resource pool. Recently I began to ponder how to accommodate for multiple frameworks requiring differing storage I/O profiles. When you consider how different workloads are within an enterprise environment, being able to support storage I/O profiles within Apache Mesos is an important feature. Unfortunately a cursory Google search did not result in anything definitive around this subject.
After a bit of research and going through the white paper again, I discovered the functionality already exists within Apache Mesos and Mesosphere Marathon — it is just a matter of implementing it. The Placement Constraints feature within Mesosphere Marathon can be used to launch frameworks to Mesos slaves with specific storage profiles. An attribute on each Mesos slave node can then be tailored to specify what type of backend storage profile is available. The attribute can be specified in a file on each Mesos slave in the /etc/mesos-slave/attributes/ directory.
For example, let’s say you have a Hadoop framework that requires a high I/O storage profile and a NGiNX framework that can get by on slightly less-performant storage. In addition, your private cloud environment has multiple storage backend devices available to it — VMware VSAN and EMC VMAX 40K arrays. If you assign the VSAN cluster to “Storage Profile 1” and the VMAX arrays to “Storage Profile 2”, they could each exist within the same Mesos cluster. The figure below shows how two different frameworks with differing storage I/O needs would be placed on Mesos slaves meeting their requirements.
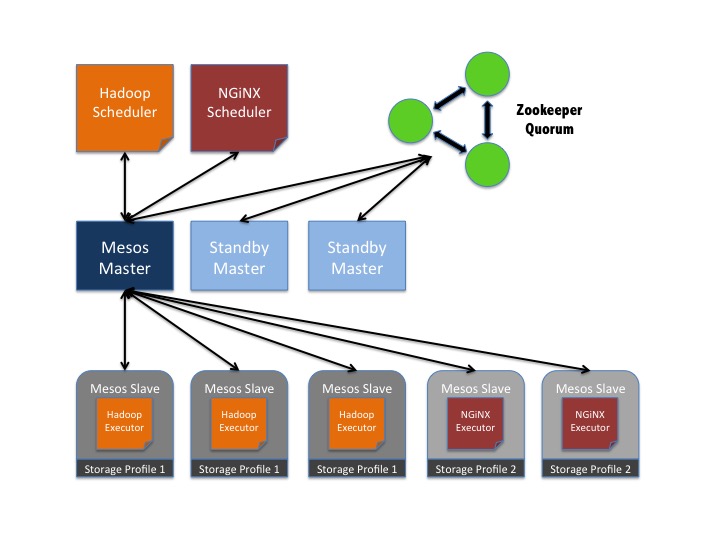
In order to provide this feature within a large-scale environment, being able to standardize and automate the deployment and configuration of the enhanced Apache Mesos cluster is key. I am already using VMware Big Data Extensions inside my private cloud environments, so naturally I looked to it first. The BDE framework allows for multiple datastores to be specified and each datastore can specify what type of storage it is — shared or local. A new Mesos cluster definition file can then be created to offer up two different node groups — one for shared storage and one for local storage. Corresponding entries through the BDE CLI or the vCenter Web Client interface can then be made to support two different types of storage.
The final piece then is creating an attribute that is assigned to each Mesos slave based on the type of storage it is deployed on. This can be accomplished by modifying the Chef cookbook for Mesos with with an entry in the /etc/mesos-slave/attributes directory. At which time, a new Mesos cluster can be deployed that has different storage I/O capabilities on the slaves.
Being able to allow certain frameworks to be placed on different physical or virtual machine nodes that present different storage characteristics is necessary in a multi-tenant, large-scale private cloud environment. Having the ability to deploy and scale the nodes in a standard, automated fashion is even more important. Fortunately the framework VMware Big Data Extensions offers is more than capable of providing the necessary tools for a cloud architect to support Apache Mesos with differing framework workloads.



