

The opportunities for VMware with Project Photon and Project Lightwave are significant. The press release stated:
Designed to help enterprise developers securely build, deploy and manage cloud-native applications, these new open source projects will integrate into VMware’s unified platform for the hybrid cloud — creating a consistent environment across the private and public cloud to support cloud-native and traditional applications. By open sourcing these projects, VMware will work with a broad ecosystem of partners and the developer community to drive common standards, security and interoperability within the cloud-native application market — leading to improved technology and greater customer choice.
What I always find interesting is the lack of discussion around the orchestration and automation of the supporting applications. The orchestration layer does not miraculously appear within a private cloud environment for the developers to consume. The pieces have to be in place in order for developers to consume the services a Mesos cluster offers them. For me, the choice is pretty obvious — expand what the Big Data Extensions framework is capable of providing. I alluded to this thought on Monday when the announcement was made.
Building on that thought and after seeing a diagram of VMware’s vision for how all the pieces tie together, I worked on a logical diagram of how the entire architecture could look like. I believe it looks something like this:
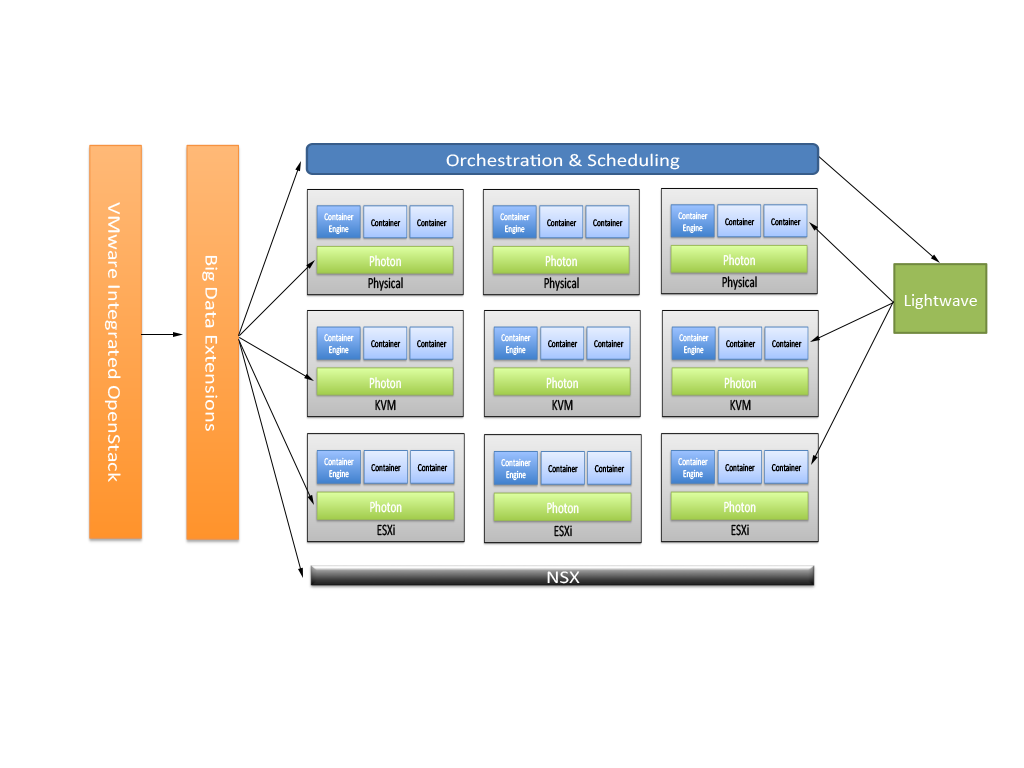
In this environment, Project Photon and Project Lightwave are able to be leveraged beyond just ESXi. By enhancing the deployment options for BDE to include ESXi on vCloud Air (not shown above), KVM and physical (through Ironic), the story is slightly changed. The story now sounds something like this:
For a developer, you choose what Cloud Native application orchestration layer (Mesos, Marathon, Chronos, CloudFoundry, etc.) you would like and communicate with it over the provided API. For operations, the deployment of the tenants within the private cloud environment can be deployed using the OpenStack API (with Heat templates). For both sides, SDLC consistency is maintained through the development process to production.
Simplicity is achieved by only interacting with two APIs — one for operations and one for development. There is large amount of work to do here. First, I need to continue to improve the OpenStack resource plugin to be production-ready. Second, testing of Project Photon inside BDE needs to take place — I imagine there will be some work to have it integrated correctly with the Chef server. Third, the deployment mechanism inside BDE needs to be enhanced to support other options. If the first two were a heavy lift, the last one is going to take a small army — but it is a challenge I am ready to take on!
Ultimately, I feel the gaps in OpenStack around Platform-as-a-Service orchestration can be solved though integrating Big Data Extensions. The framework is more robust and mature when compared to the Sahara offering. The potential is there, it just needs to be executed on.



