


Over the past weekend, I wiped my home lab environment that was running vSphere 5.5 and installed a fresh set of vSphere 6.0U1 bits. The decision to begin using vSphere 6.0 in the home lab was largely due to now longer needing vSphere 5.5 for my VCAP-DCA studying and wanting to finally begin using the Instant Clone technology for deploying Hadoop clusters with Big Data Extensions. As I had mentioned in an earlier post, the release of version 2.2 for Big Data Extensions exposed the ability to use VMware Instant Clone technology. It did not however enable the setting by default, leaving it to the vSphere administrator to determine whether or not to enable it.
Turning on the feature is simple enough. Edit the /opt/serengeti/conf/serengeti.properties file on the BDE management server, changing line 104 to state instant for the cluster.clone.service variable. The exact syntax is highlighted in the screenshot below.
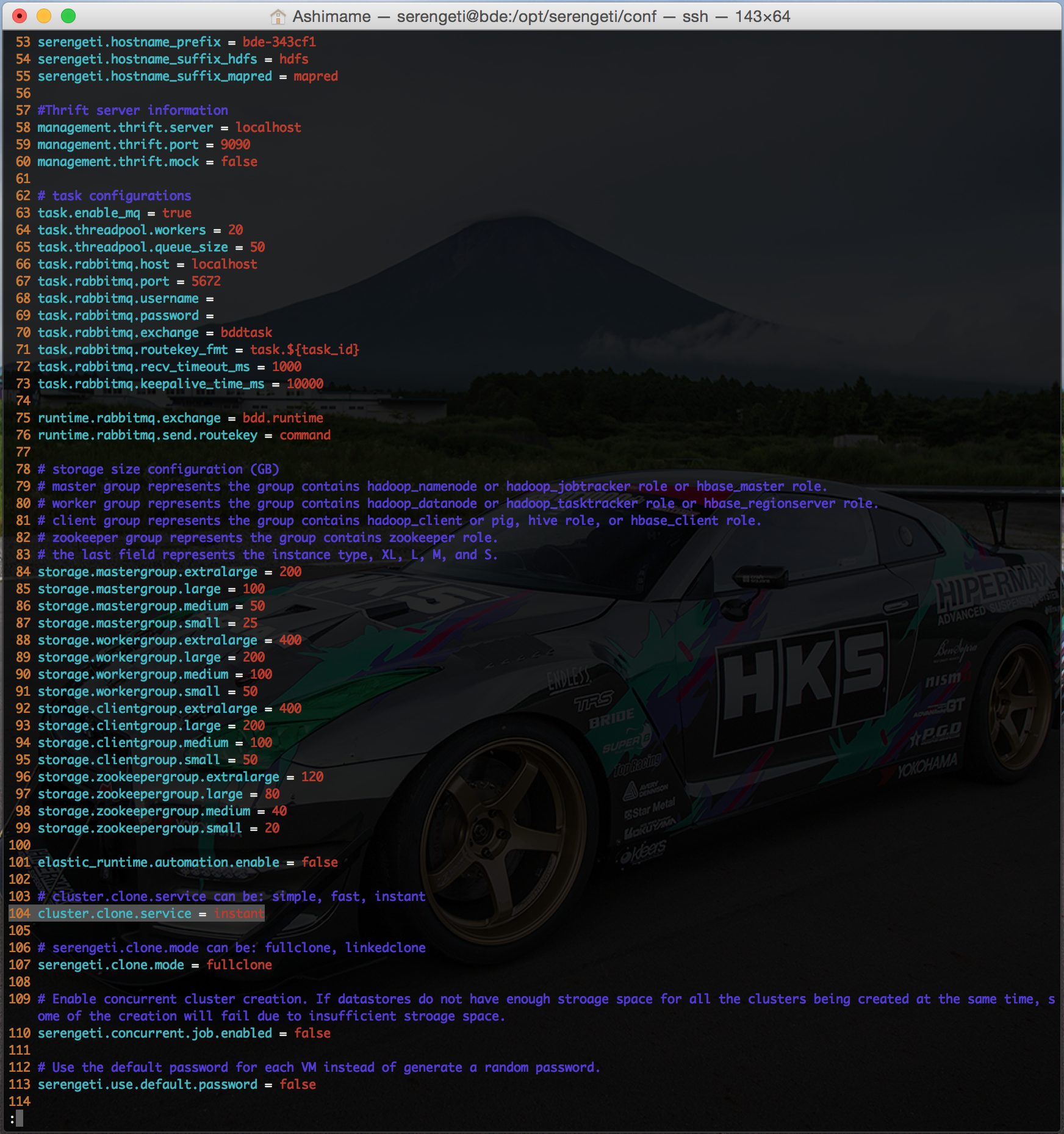
After saving the file and restarting the Tomcat service, the environment is ready to go!
For those unfamiliar with the VMware Instant Clone technology, a brief description from the VMware Blog states,
The Instant Clone capability allows admins to ‘fork’ a running virtual machine, meaning, it is not a full clone. The parent virtual machine is brought to a state where the admin will Instant Clone it, at which time the parent virtual machine is quiesced and placed in a state of a ‘parent VM’. This allows the admins to create as many “child VMs” as they please. These child VMs are created in mere seconds (or less) depending on the environment (I’ve seen child VMs created in .6 seconds). The reason these child VMs can be created so quickly is because they leverage the memory and disk of the parent VM. Once the child VM is created, any writes are placed in delta disks.
When the parent virtual machine is quiesced, a prequiesce script cleans up certain aspects of the parent VM while placing it in its parent state, allowing the child VMs to receive unique MAC addresses, UUID, and other information when they are instantiated. When spinning up the child VMs a post clone script can be used to set properties such as the network information of the VM, and/or kick off additional scripts or actions within the child VM.
The ability to deploy new Hadoop VMs in an extremely quick manner through Big Data Extensions is amazing! In addition, because of the extensibility of BDE, the VMware Instant Clone feature is used when any type of cluster deployment is initiated — Apache Spark, Apache Mesos, Apache Hadoop, etc.
VMware Instant Clone VMs
The new cloned VMs launched in less than 1 minute — for my Intel NUC home lab it was really impressive! I’ve read all the press stating Instant Clones would launch in single-digit seconds, but you never know how something is going to work in an environment you control. Seeing is believing!
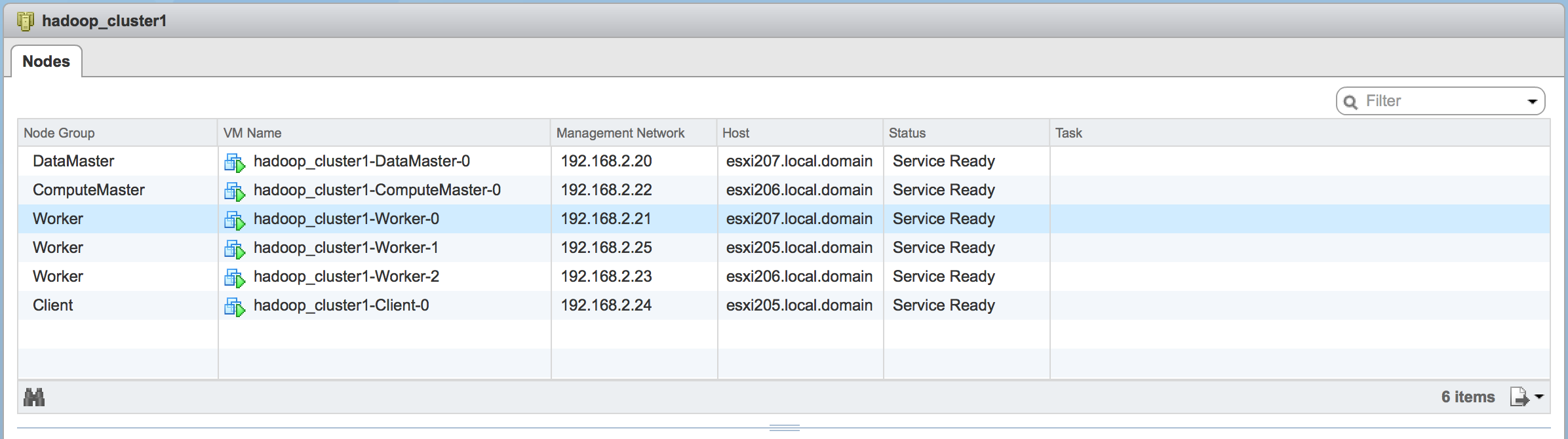
The interesting bit I did not anticipate was the fact that a single parent VM was spun up on each ESXi host inside my home lab when the first Hadoop cluster was deployed. You can see the parent VMs in a new resource pool created during the deployment that is separate from the Hadoop cluster resource pool.
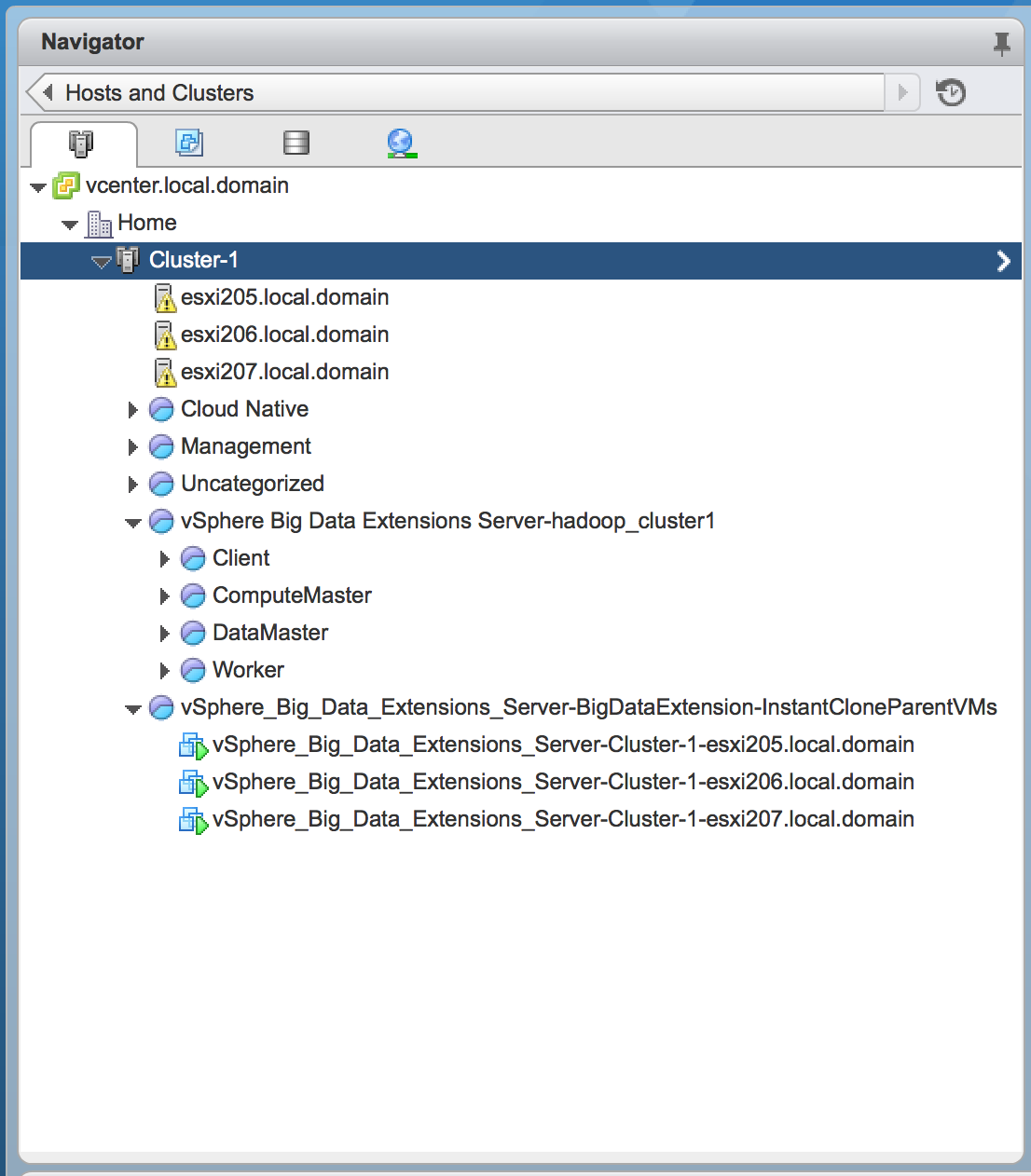
As a result of the additional VMs that did not exist when the original cluster was deployed without VMware Instant Clone, the total resource utilization across the cluster actually increased.
Cluster Utilization Before VMware Instant Clone
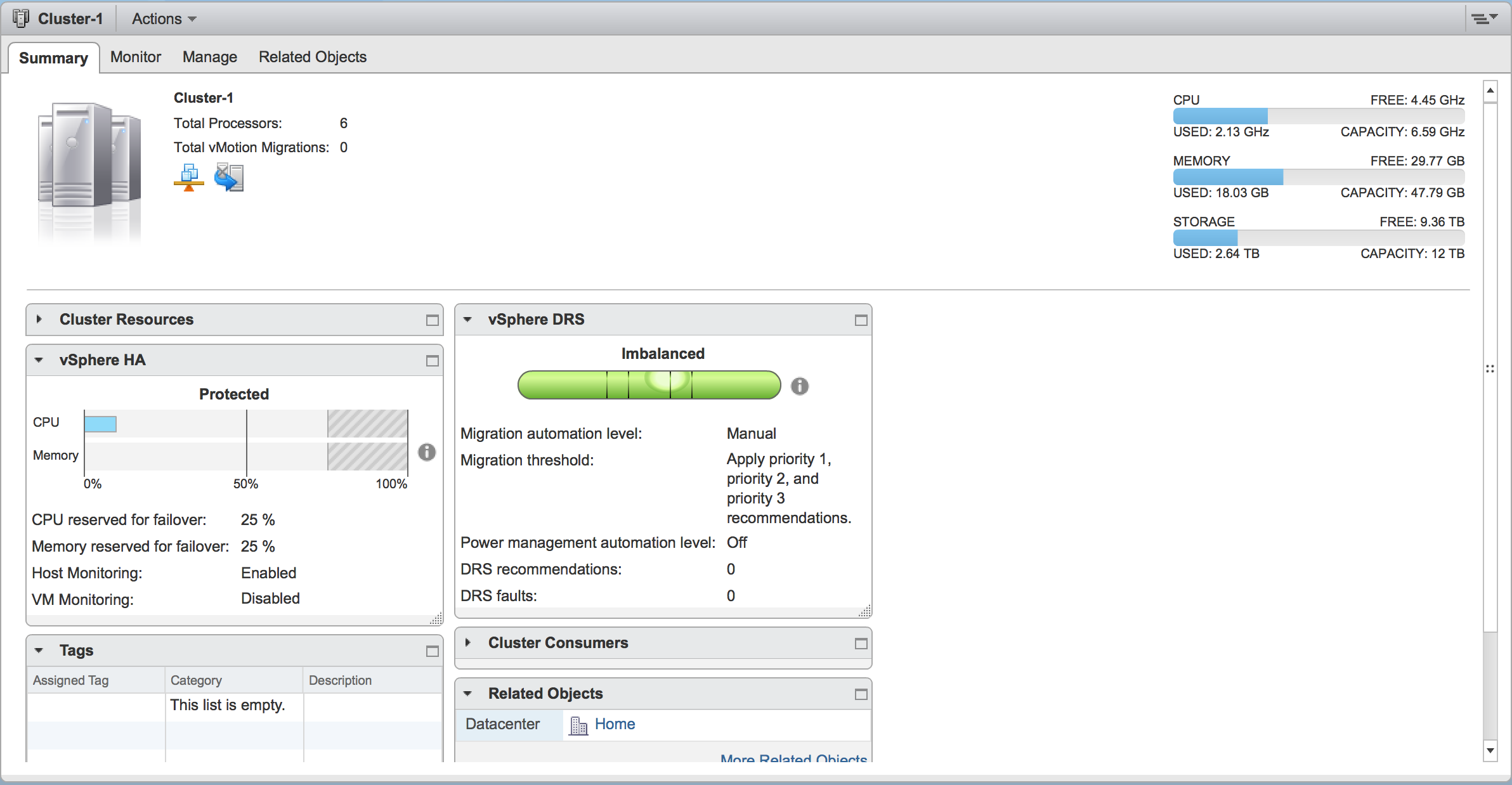
Cluster Utilization After VMware Instant Clone
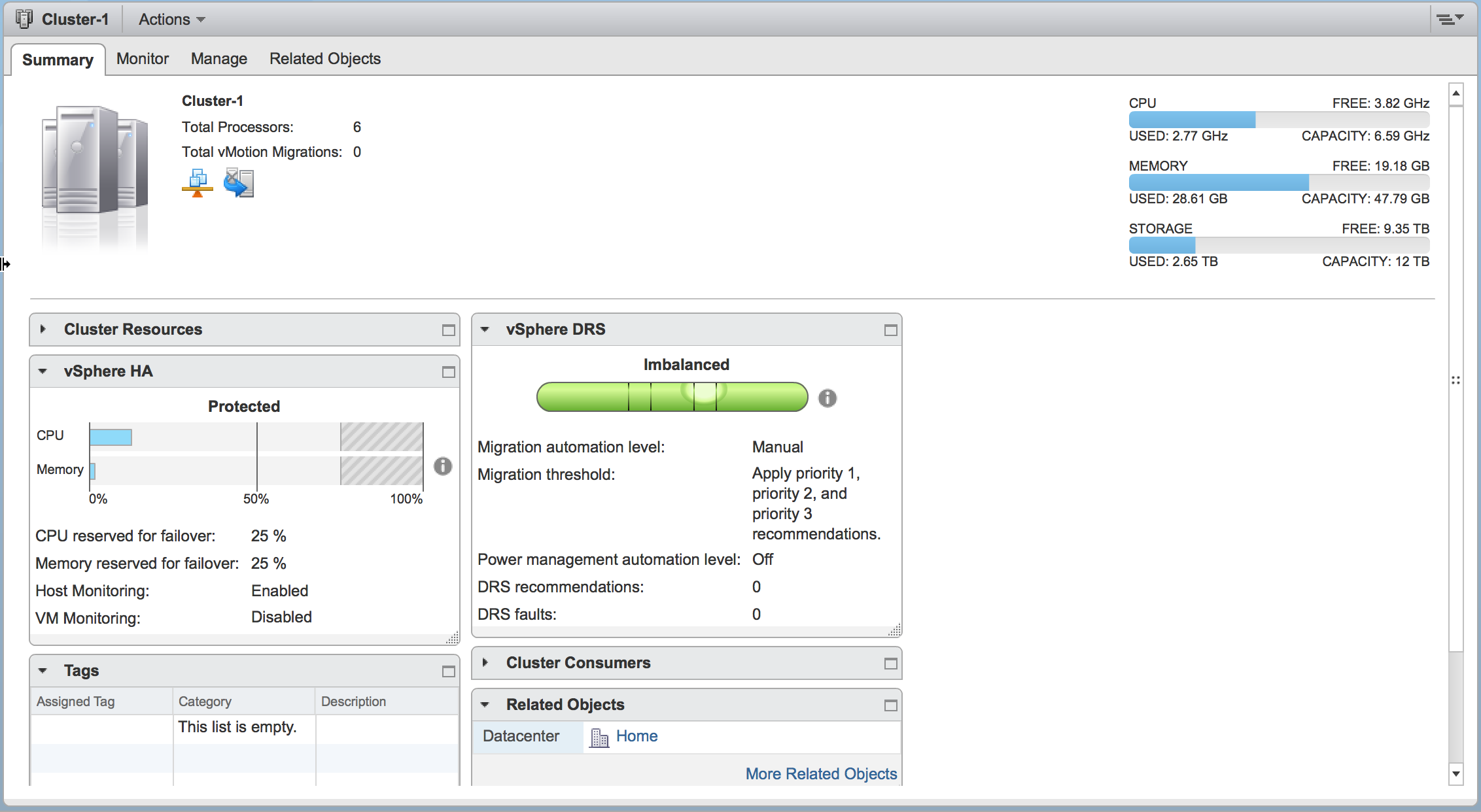
Increased Hadoop Cluster Utilization with VMware Instant Clone
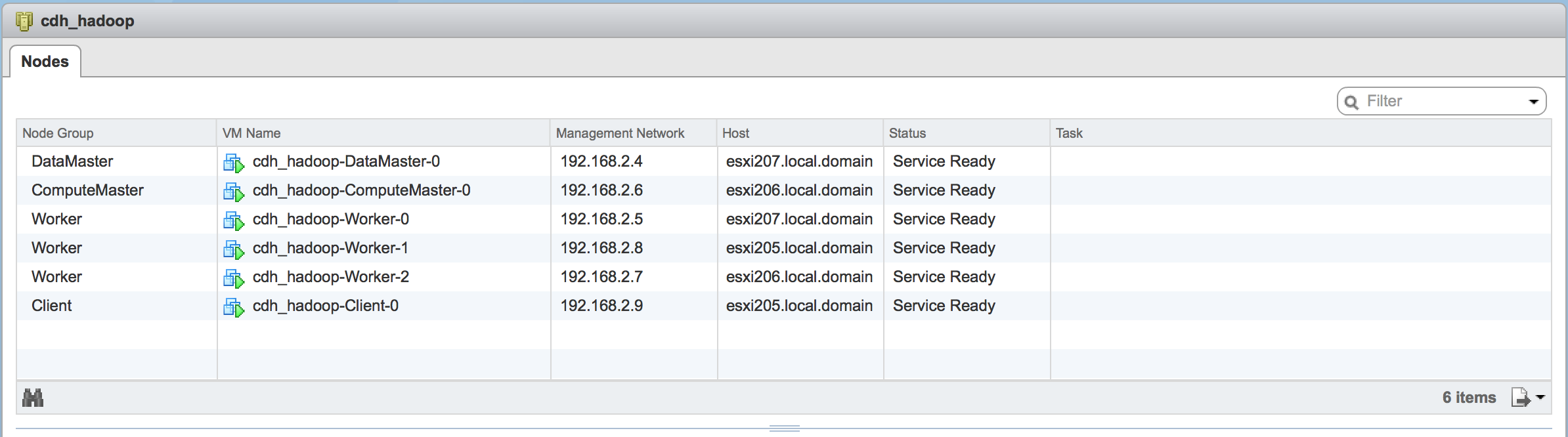
The next step was to increase the cluster size to see what sort of savings could be realized through the Instant Clone technology. I increased the number of worker nodes through BDE using the new interface.
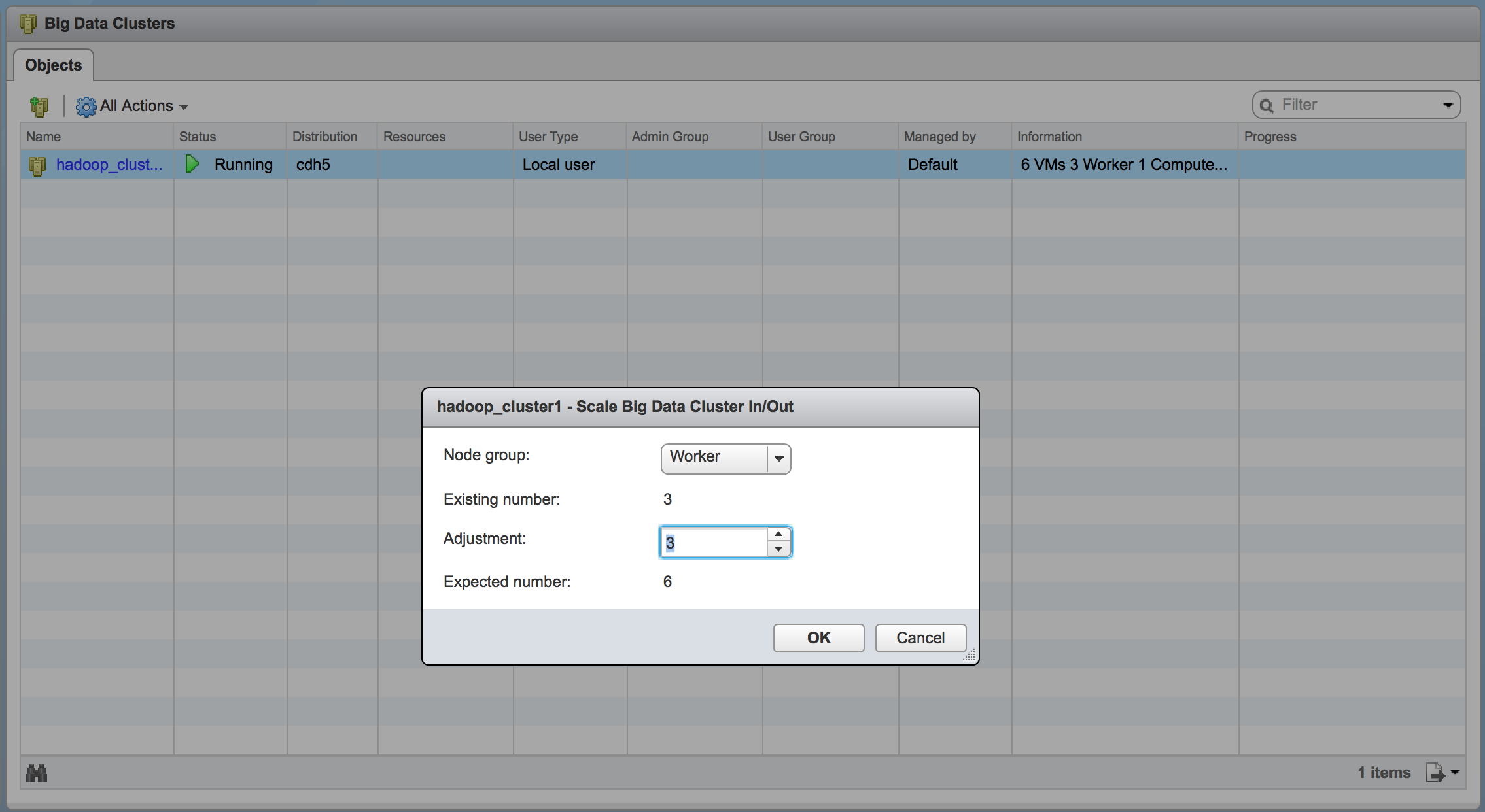
Note: The new adjustment field and showing the new node count is outstanding!
After the new nodes were added, the total cluster utilization looked like there were some savings.
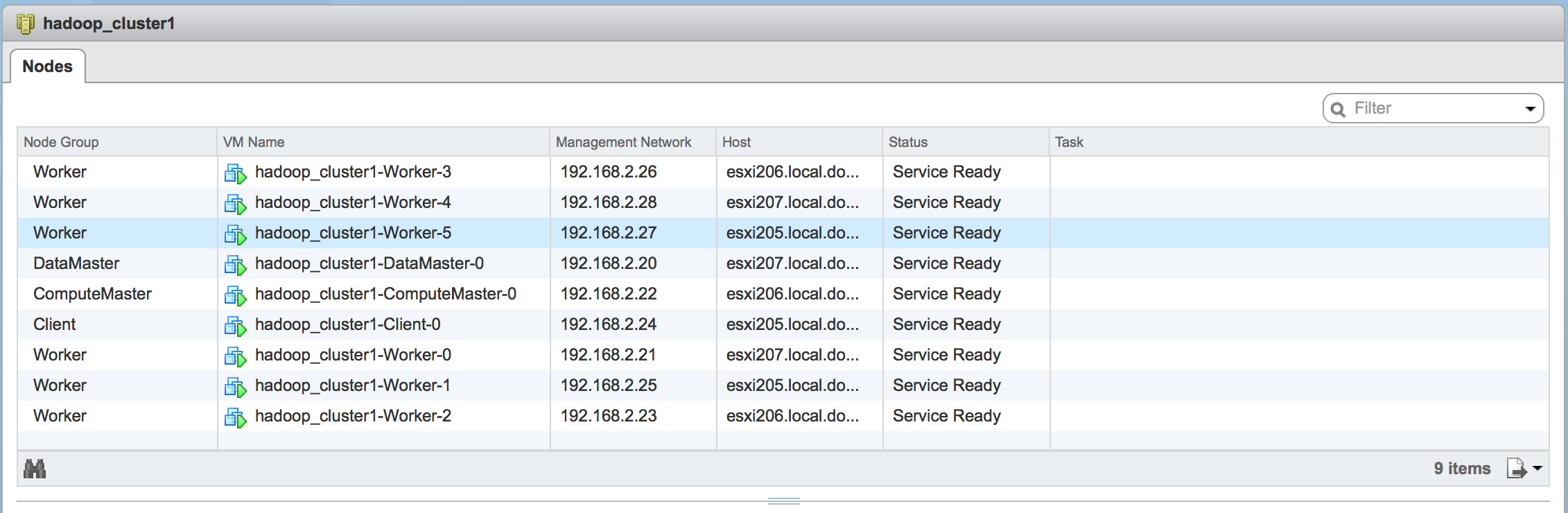

I am looking forward to using the new VMware Instant Clone technology further in the lab — including Photon nodes — to see what further savings I can get out of my home lab.



