


At VMworld 2015 in San Francisco, support for Flocker data volumes inside a VMware vSphere environment was announced. The announcement was one of the items I was most excited about hearing during the conference. The challenge of data persistence when Dockerizing workloads is prevalent in many organizations today. There are a few projects like Flocker and Rexray from EMC {Code} that are working to address this challenge. As I am working on building my own Cloud Native Application stack for a personal project, being able to maintain persistent data across the stack is key.
For those unfamiliar with Flocker, let me provide a quick overview. In short, it provides data volumes that can be attached to a Docker container that allow the container to be moved across hosts without losing data. Flocker describes the solution in a rather neat graphic.
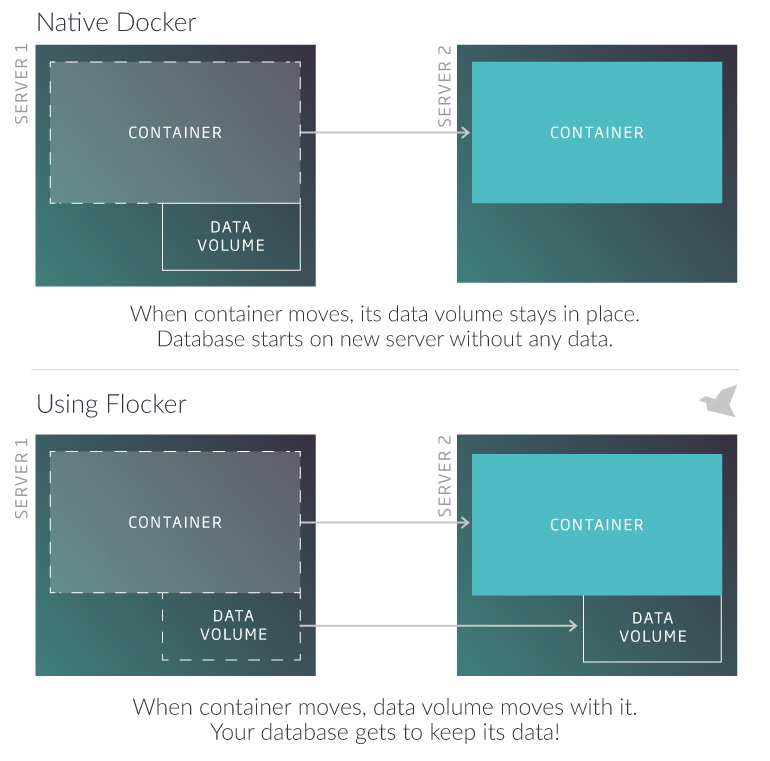
The way it works is rather simple too. There is a controller node — referred to as the Flocker Control Service — and agents that get installed on the compute nodes running the Docker containers. The vSphere driver for Flocker enables the use of a shared datastore as the place where the provisioning of the Flocker data volumes takes place. Thus allowing you to utilize a familiar virtual storage construct within your environment to provide the data persistence necessary within a Cloud Native Application.
VMware has made a driver for integrating Flocker into a vSphere environment available on GitHub. The page includes basic instructions on how to load the driver into a Flocker Agent node and begin utilizing it within a Docker container. As I looked into Flocker and how to run it within my vSphere environment, my specific use-case called for it to become part of my VMware Big Data Extensions framework, so that it could be tied to an Apache Mesos cluster with Marathon.
This project, with Flocker + Apache Mesos, is the reason I spent a good part of the past weekend working on building out a CentOS 7 template for BDE to use. I needed to be able to support running a newer version of Docker in order to support Flocker. The details on my effort to build a CentOS 7 template VM for BDE are covered in this post. Between that effort and adding Flocker support, the pieces are all starting to come together.
Flocker Support in VMware Big Data Extensions
When you look at the architecture slide on the ClusterHQ Flocker site, it becomes rather clear that adding Flocker to an Apache Mesos cluster deployment is a natural next step. The controller node could be deployed within the same VM running the Apache Mesos master or as a standalone VM. The agents can be installed and configured on the Apache Mesos slaves with Docker.
Side-Note: A few weeks back, I tried using the Debian 7 template that was released alongside the BDE Fling almost a year ago. Unfortunately it failed with a large number of Chef configuration errors when it was used to deploy an Apache Mesos cluster. Rather than fight it, I went back to using a combination of Photon and CentOS 6 for my deployments within my lab environment until I got the new CentOS 7 template working.
The ClusterHQ Flocker documentation provides directions on how to get Flocker running on an Ubuntu or CentOS 7 node. I used that documentation to help me construct the Chef recipes I needed for BDE. The first decision I made, at least for now, is to install the Flocker Control Service on a dedicated VM. By doing so, it allowed me to create a new cluster definition for a Mesos cluster with Flocker support, while leaving the original cluster specification file untouched.
/opt/serengeti/www/specs/Ironfan/mesos/flocker/spec.json
1 {
2 "nodeGroups":[
3 {
4 "name": "Zookeeper",
5 "roles": [
6 "zookeeper"
7 ],
8 "groupType": "zookeeper",
9 "instanceNum": "[3,3,3]",
10 "instanceType": "[SMALL]",
11 "cpuNum": "[1,1,64]",
12 "memCapacityMB": "[7500,3748,min]",
13 "storage": {
14 "type": "[SHARED,LOCAL]",
15 "sizeGB": "[2,2,min]"
16 },
17 "haFlag": "on"
18 },
19 {
20 "name": "Master",
21 "description": "The Mesos master node",
22 "roles": [
23 "mesos_master",
24 "mesos_chronos",
25 "mesos_marathon"
26 ],
27 "groupType": "master",
28 "instanceNum": "[2,1,2]",
29 "instanceType": "[MEDIUM,SMALL,LARGE,EXTRA_LARGE]",
30 "cpuNum": "[1,1,64]",
31 "memCapacityMB": "[7500,3748,max]",
32 "storage": {
33 "type": "[SHARED,LOCAL]",
34 "sizeGB": "[1,1,min]"
35 },
36 "haFlag": "on"
37 },
38 {
39 "name": "Flocker Control",
40 "description": "Flocker control node",
41 "roles": [
42 "flocker_control"
43 ],
44 "groupType": "master",
45 "instanceNum": "[1,1,1]",
46 "instanceType": "[SMALL,MEDIUM]",
47 "cpuNum": "[1,1,16]",
48 "memCapacityMB": "[3748,3748,max]",
49 "storage": {
50 "type": "[SHARED,LOCAL]",
51 "sizeGB": "[1,1,min]"
52 },
53 "haFlag": "on"
54 },
55 {
56 "name": "Slave",
57 "description": "The Mesos slave node",
58 "roles": [
59 "mesos_slave",
60 "mesos_docker",
61 "flocker_agent"
62 ],
63 "instanceType": "[MEDIUM,SMALL,LARGE,EXTRA_LARGE]",
64 "groupType": "worker",
65 "instanceNum": "[3,1,max]",
66 "cpuNum": "[1,1,64]",
67 "memCapacityMB": "[7500,3748,max]",
68 "storage": {
69 "type": "[SHARED,LOCAL]",
70 "sizeGB": "[1,1,min]"
71 },
72 "haFlag": "off"
73 }
74 ]
75 }
Note: I enabled HA support for the Flocker Control Node within the specification file since it is only going to be deploying a single VM within the cluster.
The corresponding MAP entry included the following lines.
/opt/serengeti/www/specs/map
30 {
31 "vendor" : "Mesos",
32 "version" : "^(\\d)+(\\.\\w+)*",
33 "type" : "Mesos with Flocker Cluster",
34 "appManager" : "Default",
35 "path" : "Ironfan/mesos/flocker/spec.json"
36 },
With the JSON cluster specification file created and the MAP entry added, the next step is to create two new Chef roles — flocker_control and flocker_agent.
/opt/serengeti/chef/roles/flocker_control.rb
1 name 'flocker_control' 2 description 'Deploy the Flocker Control Node to support an Apache Mesos cluster.' 3 4 run_list *%w[ 5 role[basic] 6 flocker::default 7 flocker::control 8 ] 9
/opt/serengeti/chef/roles/flocker_agent.rb
1 name 'flocker_agent' 2 description 'Deploy the Flocker agent on Apache Mesos worker node.' 3 4 run_list *%w[ 5 role[basic] 6 flocker::default 7 flocker::agent 8 ] 9
The flocker-control Chef role will be used to install and configure the standalone VM running the Flocker Control Service. The flocker-agent will be used to configure the Flocker Agent on each of the Apache Mesos worker nodes.
Chef Recipes for Flocker
I broke the Chef recipes into two — one for the Control node and one for the Agents. In addition to the primary recipes for installation and configuration, I created a library recipe, attributes file and several templates. I have included the recipes for the Control and Agent roles below, the remaining files can be downloads from the GitHub repository.
/opt/serengeti/chef/cookbooks/flocker/reciptes/default.rb
1 # Cookbook Name:: flocker
2 # Recipe:: default
3
4 include_recipe "java::sun"
5 include_recipe "hadoop_common::pre_run"
6 include_recipe "hadoop_common::mount_disk"
7 include_recipe "hadoop_cluster::update_attributes"
8
9 set_bootstrap_action(ACTION_INSTALL_PACKAGE, 'flocker', true)
10
11 # Setup the new repositories
12 template '/etc/yum.repos.d/clusterhq.repo' do
13 source 'clusterhq.repo.erb'
14 action :create
15 end
16
17 # Dependency packages
18 %w{clusterhq-flocker-node clusterhq-flocker-cli}.each do |pkg|
19 package pkg do
20 action :install
21 end
22 end
23
24 clear_bootstrap_action
/opt/serengeti/chef/cookbooks/flocker/recipes/control.rb
1 #
2 # Cookbook Name:: flocker
3 # Recipe:: control
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License
16
17 include_recipe 'flocker::install'
18
19 set_bootstrap_action(ACTION_INSTALL_PACKAGE, 'flocker_control', true)
20
21 conf_dir = node[:flocker][:conf_dir]
22 temp_dir = node[:flocker][:temp_dir]
23 directory conf_dir do
24 owner 'root'
25 group 'root'
26 mode '0700'
27 action :create
28 end
29
30 template '/etc/flocker/cluster.key' do
31 source 'cluster.key.erb'
32 mode '0600'
33 owner 'root'
34 group 'root'
35 action :create
36 end
37
38 template '/etc/flocker/cluster.crt' do
39 source 'cluster.crt.erb'
40 mode '0600'
41 owner 'root'
42 group 'root'
43 action :create
44 end
45
46 template '/etc/flocker/control-service.crt' do
47 source 'control-service.crt.erb'
48 mode '0600'
49 owner 'root'
50 group 'root'
51 action :create
52 end
53
54 template '/etc/flocker/control-service.key' do
55 source 'control-service.key.erb'
56 mode '0600'
57 owner 'root'
58 group 'root'
59 action :create
60 end
61
62 # Generate authentication certificates
63 #execute 'generate_system_certs' do
64 # cwd conf_dir
65 # command 'flocker-ca initialize $CLUSTERNAME'
100 # Start the Flocker Control service
101 is_control_running = system("systemctl status #{node[:flocker][:control_service_name]}")
102 service "restart-#{node[:flocker][:control_service_name]}" do
103 service_name node[:flocker][:control_service_name]
104 supports :status => true, :restart => true
105
106 end if is_control_running
107
108 service "start-#{node[:flocker][:control_service_name]}" do
109 service_name node[:flocker][:control_service_name]
110 action [ :enable, :start ]
111 supports :status => true, :restart => true
112
113 end
114
115 # Register with cluster_service_discovery
116 provide_service(node[:flocker][:control_service_name])
117 clear_bootstrap_action
/opt/serengeti/chef/cookbooks/flocker/recipes/agent.rb
1 #
2 # Cookbook Name:: flocker
3 # Recipe:: agent
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License
16
17 include_recipe 'flocker::install'
18
19 set_bootstrap_action(ACTION_INSTALL_PACKAGE, 'flocker_agent', true)
20
21 # Wait for the Flocker control node to be setup and registered
22 wait_for_flocker_control
23
24 conf_dir = node[:flocker][:conf_dir]
25 directory conf_dir do
26 owner 'root'
27 group 'root'
28 mode '0700'
29 action :create
30 end
31
32 controls_ip = flocker_control_ip
33
34 template '/etc/flocker/agent.yml' do
35 source 'agent.yml.erb'
36 action :create
37 variables(
38 control_node: controls_ip
39 )
40 end
41
42 template '/etc/flocker/node.crt' do
43 source 'node.crt.erb'
44 action :create
45 mode '0600'
46 owner 'root'
47 group 'root'
48 end
49
50 template '/etc/flocker/node.key' do
51 source 'node.key.erb'
52 action :create
53 mode '0600'
54 owner 'root'
55 group 'root'
56 end
57
58 template '/etc/flocker/cluster.crt' do
59 source 'cluster.crt.erb'
60 action :create 61 mode '0600'
62 owner 'root'
63 group 'root'
64 end
65
66 # Fix agent.yml hostname string
67 # hostname: ["blah.local.domain"]
68 execute 'fix agent.yml hostname' do
69 cwd conf_dir
70 command 'sed -i \'s/\["/"/g\' /etc/flocker/agent.yml && sed -i \'s/"\]/"/g\' /etc/flocker/agent.yml'
71 end
72
73 # Install additional packages
74 %w{git}.each do |pkg|
75 package pkg do
76 action :install
77 end
78 end
79
80 execute "install-python-pip" do
81 command 'curl "https://bootstrap.pypa.io/get-pip.py" -o "get-pip.py" && python get-pip.py'
82 end
83
84 # Install the VMware vsphere-flocker-driver
85 execute 'install vmware-flocker-driver' do
86 command 'pip install git+https://github.com/vmware/vsphere-flocker-driver.git'
87 end
88
89 # Start the two Flocker agent services
90 service 'flocker-dataset-agent' do
91 supports :status => true, :restart => true, :reload => false
92 action [ :enable, :start ]
93 end
94
95 service 'flocker-container-agent' do
96 supports :status => true, :restart => true, :reload => false
97 action [ :enable, :start ]
98 end
99
100 provide_service(node[:flocker][:agent_service_name])
101 clear_bootstrap_action
VMware vSphere Flocker Driver
The necessary bits for utilizing the Flocker driver are built into the Chef recipes themselves. However, since the GitHub page does a good job of providing an overview, I would like to highlight the specific bits of the Chef recipes that coincide with that documentation.
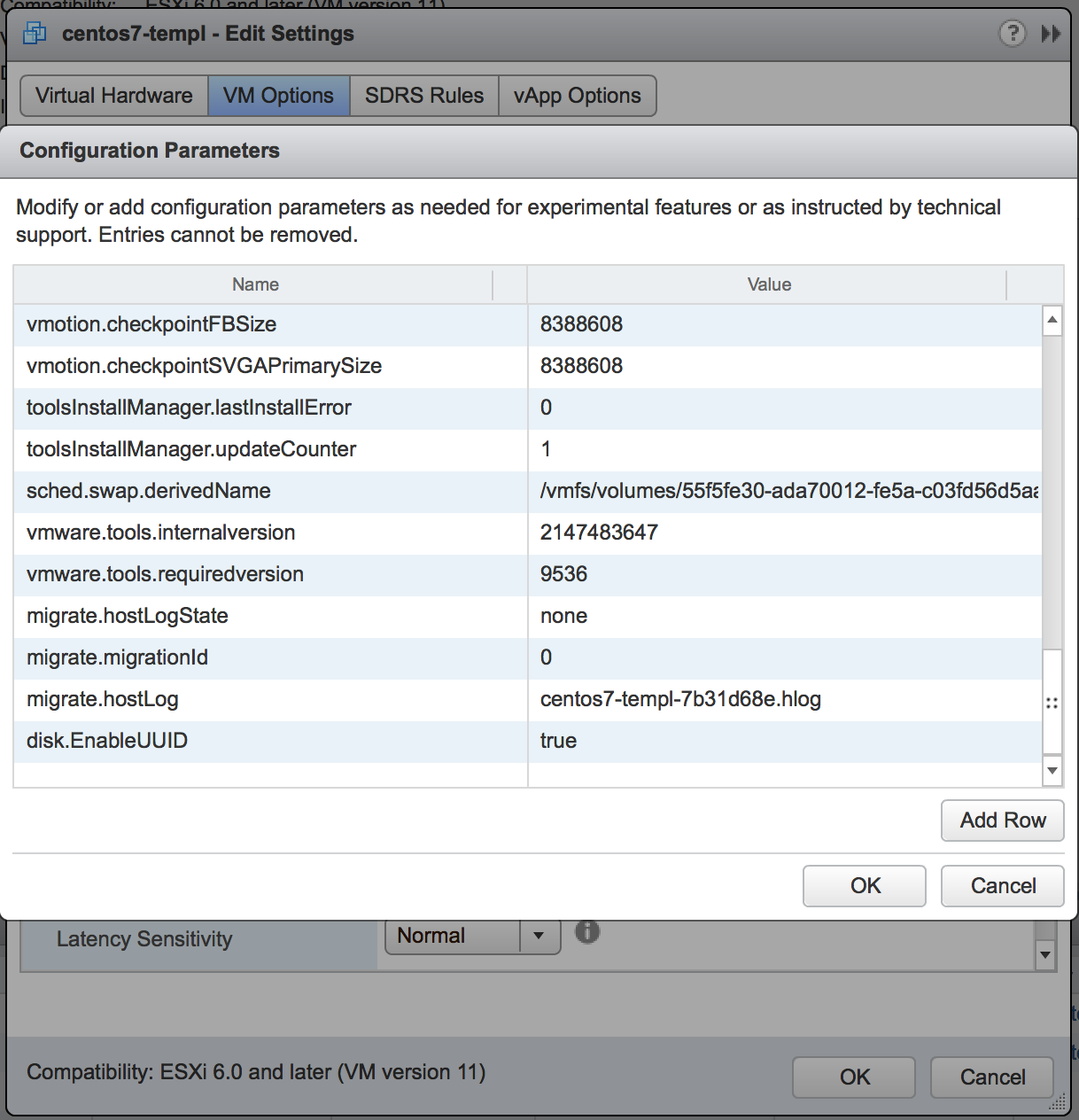
I started off my modifying my CentOS 7 VM template for BDE to included the advanced setting in the VMX file.
disk.EnableUUID = "TRUE"
The next step was to mark a datastore for Flocker to use for the shared volumes. Because I already had BDE in my environment and it was currently pointing to three datastores, I went ahead modified my implementation a bit. The three datastores I did have BDE utilizing were actually part of a single Storage DRS cluster. I went ahead and remove the Storage DRS cluster and left the three datastores alone. From there, I selected just a single datastore for BDE to use going forward and created the necessary Flocker folder.
Deploying an Apache Mesos cluster with Flocker support
With all of the pieces in place, the environment is ready for a new Apache Mesos cluster to be deployed through the BDE framework. Using the vSphere Web Client, I deployed a new cluster for testing. Once the cluster was deployed through BDE and fully configured using the new Chef recipes, I verified that the Apache Mesos, Mesosphere Marathon and Chronos interfaces were all online.
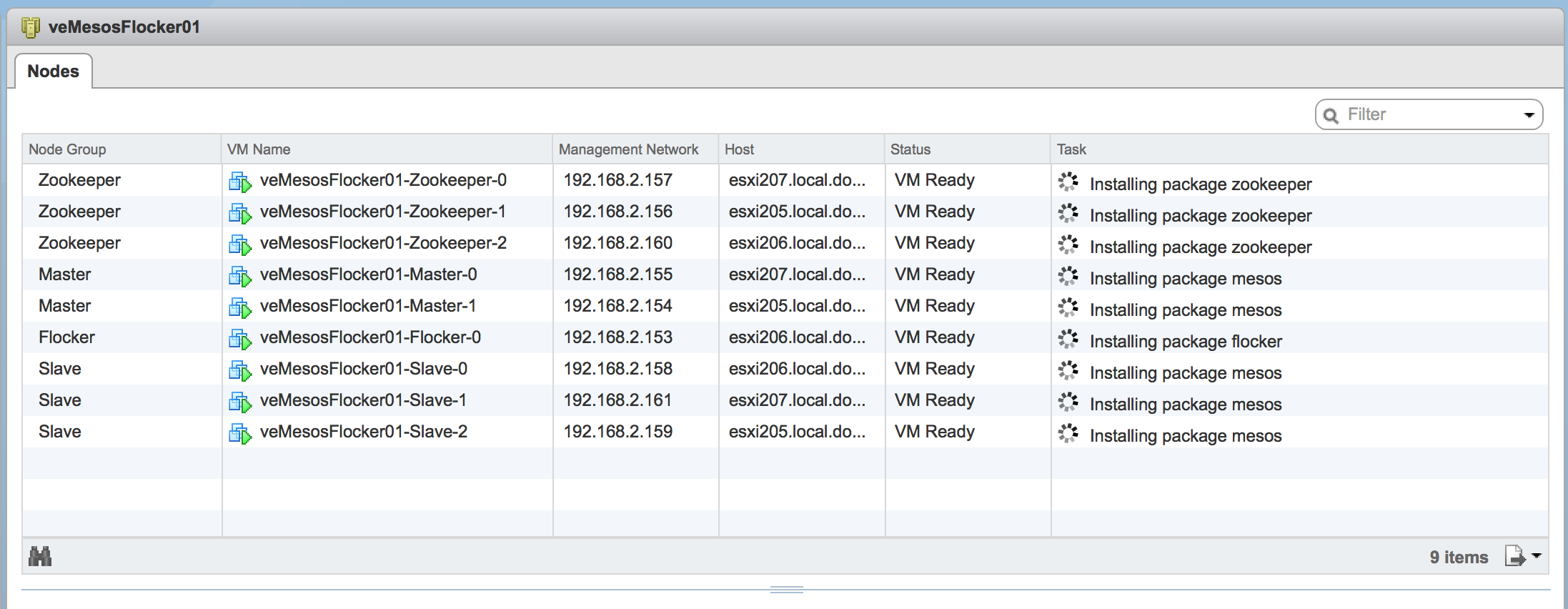
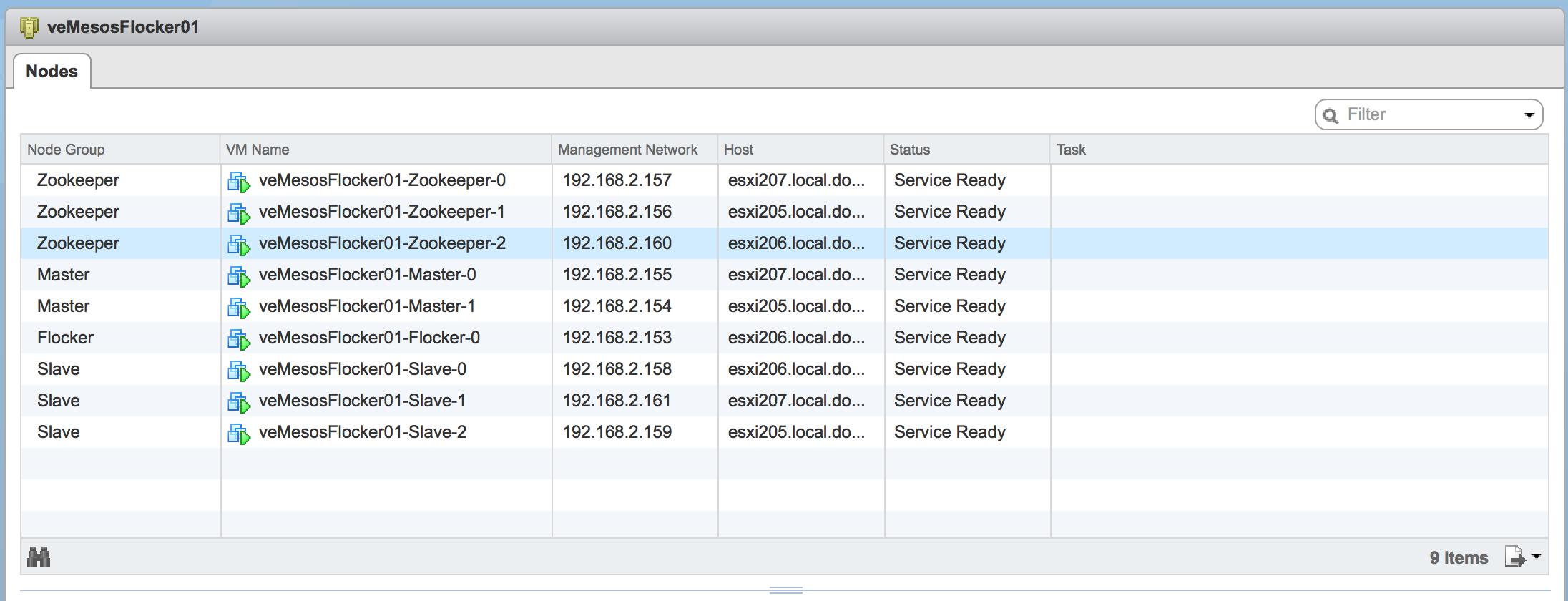

The cluster is ready for a workload to be deployed into it.
Conclusion
VMware is making significant strides into the Cloud Native Apps space with the ability to support Docker, Apache Mesos, Kubernetes and now also Flocker. In my opinion, being able to provide a simple deployment framework for these applications through VMware Big Data Extensions is a key success factor. Tying these pieces all together tells a very compelling story for organizations already using the VMware SDDC within their environments and transitioning to the Cloud Native Apps arena. Future posts will revolve around my own work in the space to build a Cloud Native distributed application running entirely on a vSphere environment.
I am very excited about this project and getting Flocker in place was a critical factor for my success. As always, all of the necessary files to add support for Flocker into VMware Big Data Extensions are available on the Virtual Elephant GitHub repository.
Stay tuned and if you have any questions about what I’ve covered in these posts, please reach out to me over Twitter, LinkedIn or email. Enjoy!



