


Finding a post for today’s #vDM30in30 post was a challenge. When I set out to complete the challenge I knew the later posts would become more difficult as the weeks wore on, but I didn’t think the challenge would arise so quickly (i.e. the end of week 2). For whatever reason, I could not decide on a topic that I wanted to write about until late this evening. As I was working on the portion of my VCDX design that covers Monitoring and the supporting infrastructure, I found myself thinking about how to incorporate a proper vRealize Log Insight system into the design. That led to tonight’s topic, Log Insight clusters.
I have learned a VCDX design should never include a VMware product just for the sake of including it. The need for vRealize Log Insight in the current design I am working on is justified by the requirements. As I have learned to use Log Insight more extensively over the past year and a half, the strengths of the product continue to amaze me. One such strength is the ease with which it is possible to incorporate a high availability feature into the platform. If you are unfamiliar with vRealize Log Insight, it is an analytics and remote logging platform that acts as a remote syslog server capable of parsing hundreds of thousands of log messages per day. The regular expression capabilities of the product are second-to-none — much better and more reliable than similar products like Splunk (IMHO).
The design I am working on is leveraging VMware Cloud Foundation (VCF) as the hardware and SDDC platform. With this requirement comes certain constraints, including the deployment method VCF uses for vRealize Log Insight. When VCF creates the management domain, it deploys a single vRealize Log Insight virtual appliance. Because I have a requirement to store all relevant log files in a central location, leveraging the existing vRealize Log Insight virtual appliance makes sense. However a single node is a single point of failure, which is not adequate for a production architecture, let alone a VCDX design.
So how can vRealize Log Insight be enhanced to handle a failure? Why a cluster of course! The Engineering team responsible for vRealize Log Insight were kind enough to build a clustering feature into the product and even included an internal load balancer as well! Having a cluster of nodes allows the environment to handle an eventual failure event — whether it is because the VM operating system becomes unresponsive or the underlying ESXi node fails altogether. Once configured, the VIP specified for use by the internal load balancer should be the IP and/or FQDN all of the downstream services use for sending syslog messages.
Configure a Log Insight Cluster
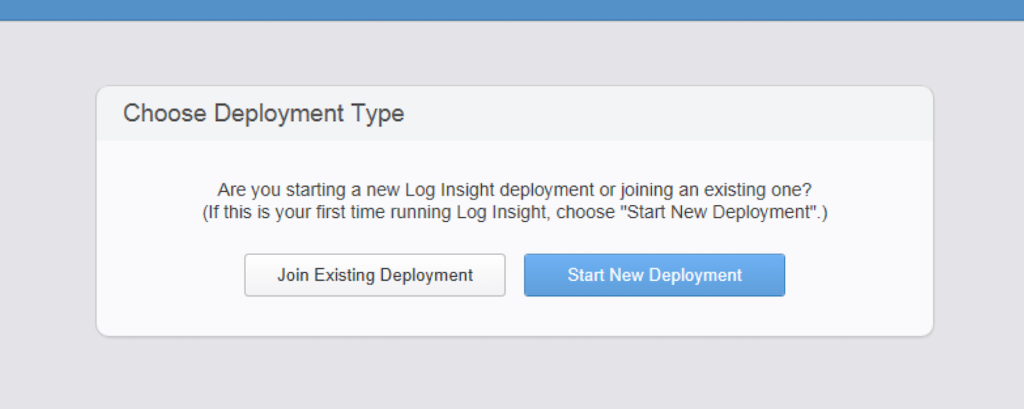
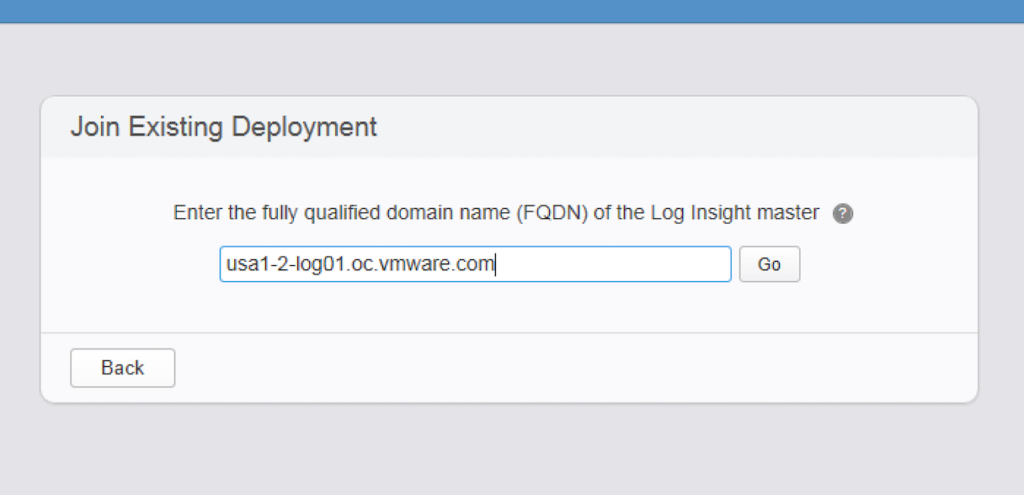
The creation of a Log Insight cluster is relatively straightforward and I will quickly go through the steps. Remember the Log Insight nodes have a requirement to exist on the same L2 network — no L3 support for multiple geographic clusters currently. Simply deploy three Log Insight virtual appliances and power them on. Once the OS has been started, log into the web UI for the additional instances and perform the following steps.
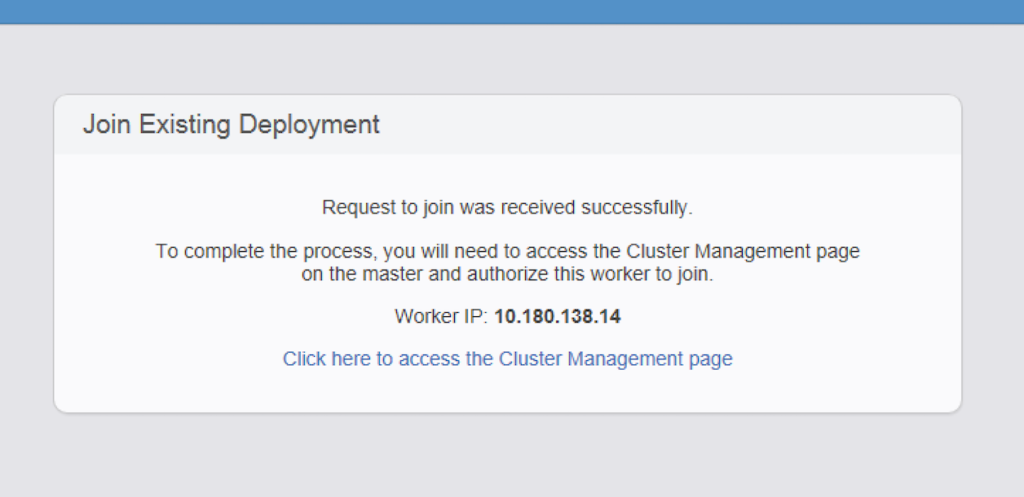

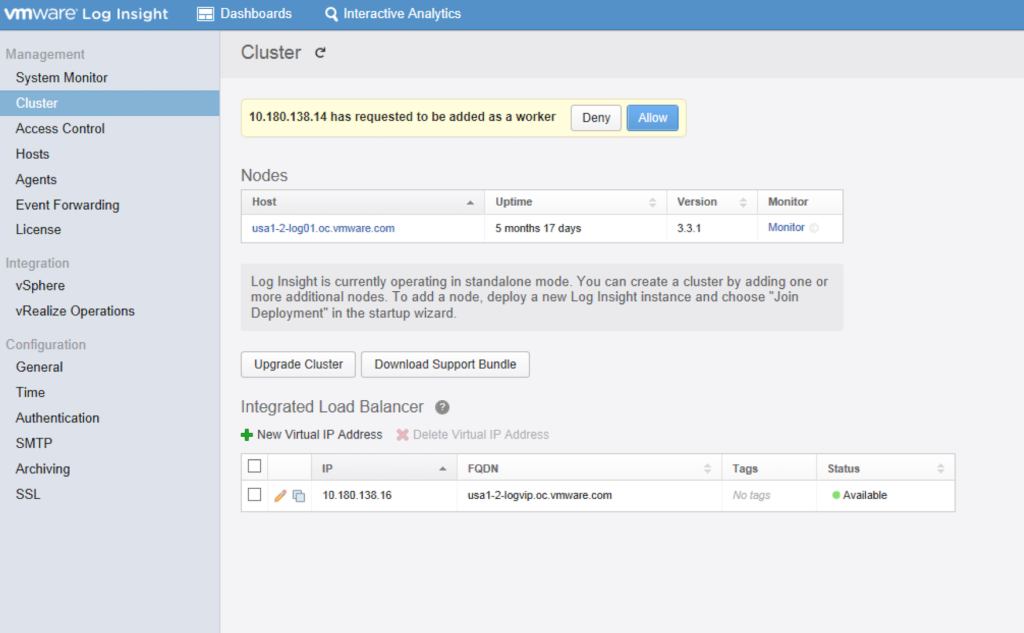
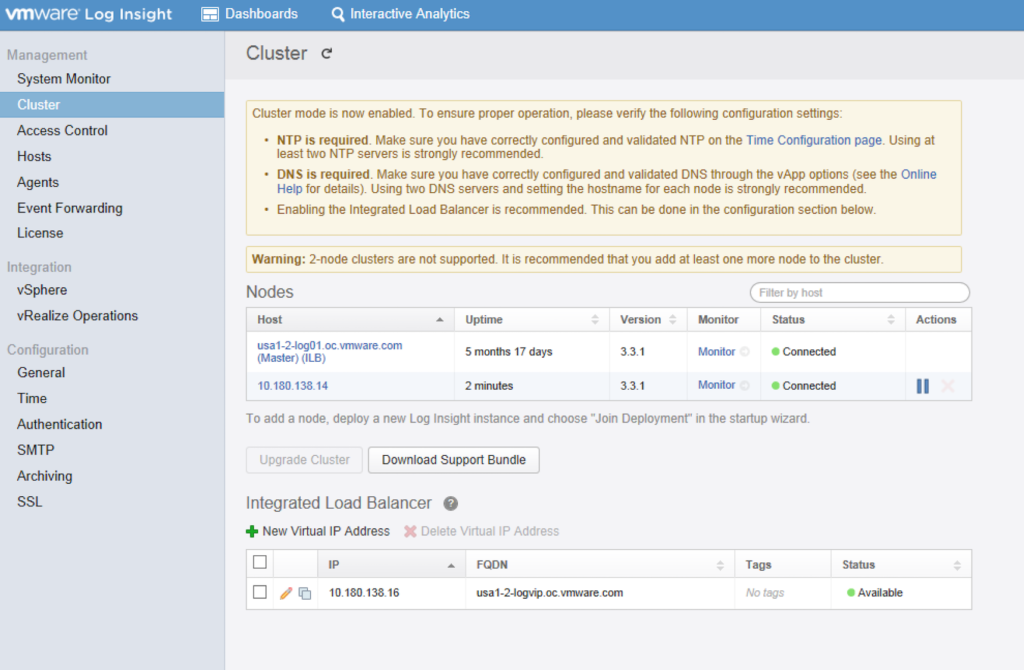
Add a third node in and you have a working vRealize Log Insight cluster, capable of distributing incoming log messages between multiple nodes. Depending on the SLA for the environment, you can increase the number of nodes within the cluster to meet the requirements.
Fortunately for me, the weekend posts were written on election night and are scheduled to auto-publish. Hopefully that will allow me to spend some much needed time working on VCDX design documentation. The December 1 deadline is fast approaching!



