

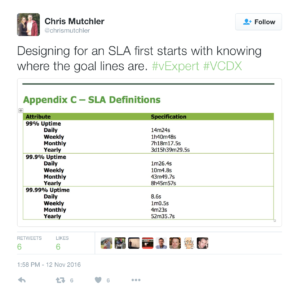
 Over the weekend I focused on two things — taking care of my six kids while my wife was out of town and documenting my VCDX design. During the course of working through the Monitoring portion of the design I found myself focusing on the technical reasons for some of the design decisions I was making to meet the SLA requirements of the design. That prompted the tweet you see the the left. When working on any design, you have to understand where the goal posts are in order to make intelligent decisions. With regards to an SLA, it means understanding what the SLA target is and on what frequency the SLA is being calculated. As you can see from the image, a SLA calculated against a daily metric will vary a considerable amount from a SLA calculated on a weekly or monthly basis.
Over the weekend I focused on two things — taking care of my six kids while my wife was out of town and documenting my VCDX design. During the course of working through the Monitoring portion of the design I found myself focusing on the technical reasons for some of the design decisions I was making to meet the SLA requirements of the design. That prompted the tweet you see the the left. When working on any design, you have to understand where the goal posts are in order to make intelligent decisions. With regards to an SLA, it means understanding what the SLA target is and on what frequency the SLA is being calculated. As you can see from the image, a SLA calculated against a daily metric will vary a considerable amount from a SLA calculated on a weekly or monthly basis.
So what can be done to meet the target SLA? If the monitoring solution is inside the environment, shouldn’t it have a higher target SLA than the thing it is monitoring? As I looked at the downtime numbers, I realized there were places where vSphere HA would not be adequate (by itself) to meet the SLA requirement of the design if it was being calculated on a daily or weekly basis. The ever elusive 99.99% SLA target eliminates vSphere HA altogether if it is being calculated on any less than a yearly basis.
As the architect of a project it is important to discuss the SLA requirements with the stakeholders and understand where the goal posts are. Otherwise you are designing in the vacuum of space with no GPS to guide you to the target.
SLAs within SLAs
The design I am currently working on had requirements for a central log repository and a SLA target of 99.9% for the tenant workload domain, calculated on a monthly basis. As I worked through the design decisions, I came to realize however the central logging capability that vRealize Log Insight is providing to the environment should be more resilient than the 99.9% uptime of the workload domain it is supporting. This type of SLA within a SLA is the sort of thing you may find yourself having to design against. So how could I increase the uptime to be able to support a higher target SLA for Log Insight?
The post on Friday discussed the clustering capabilities of Log Insight and that came about as I was working through this problem. If the clustering capability of Log Insight could be leveraged to increase the uptime of the solution, even on physical infrastructure only designed to provide a lower 99.9% SLA, then I could meet the higher target sub-SLA. By including a 3-node Log Insight cluster and creating anti-affinity rules on the vSphere cluster to ensure the Log Insight virtual appliances were never located on the same physical node, I was able to increase the SLA potential of the solution. The last piece of the puzzle was the incorporation of the internal load balancing mechanism of Log Insight and using the VIP as the target for all of the systems remote logging functionality. This allowed me to create a central logging repository with a higher target SLA than the underlying infrastructure SLA.
Designing for and justifying the decisions made to support a SLA is one of the more trying issues in any architecture, at least in my mind. Understanding how decisions made influence positively or negatively the SLA goals of the design is something every architect will need to do. This is one area where I was weak during my previous VCDX defense and as not able to accurately articulate. After spending significant time thinking through the key points of my current design, I have definitely learned more and have been able to understand what effects the choices I am making have.
The opinions expressed above are my own and as I have not yet acquired my VCDX certification, these opinions may not be shared by those who have.



