Tanzu Kubernetes Grid (TKG) is an enterprise-grade Kubernetes distribution that provides a consistent and secure way to deploy and operate Kubernetes clusters cross multiple cloud and on-premises environments. This article will cover several of the common lifecycle operations that Tanzu Kubernetes Grid automates inside a VMware SDDC environment to allow for seamless operation of the Kubernetes clusters.
Node Failure Automation
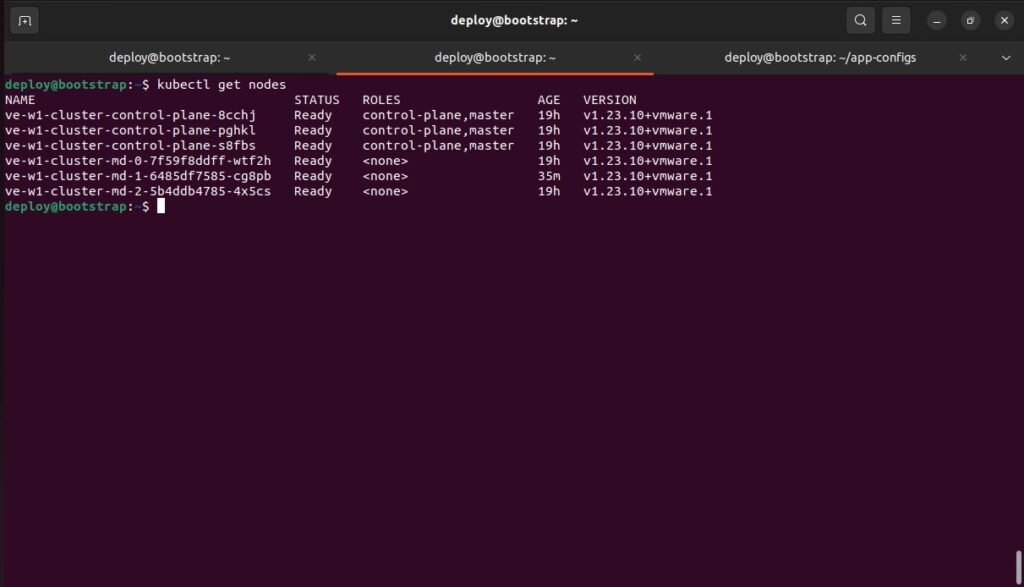
Tanzu Kubernetes Grid provides automated monitoring of Kubernetes clusters. The configuration model is used to leverage the manifest created at the time of deployment of the cluster and monitor for failures within the cluster. The self-healing capabilities of TKG allow for nodes within a VMware SDDC environment to be automatically deleted and replaced with new nodes in a fashion that does not require any human intervention.
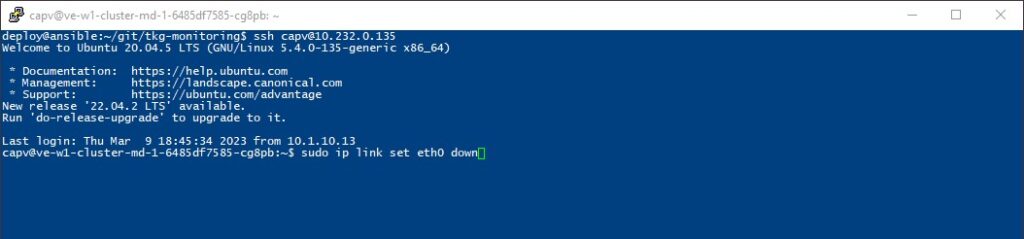
For demonstration purposes, I am going to simulate a network failure on one of the worker nodes. To perform this action, I am going to SSH into one of the worker nodes and then take the eth0 interface offline. This will trigger the monitoring processes that are running on the TKG Management Cluster and kick off a workflow that will do the following:
Delete the failed worker node
Clone the TKG template to create a new worker node
Configure the new worker node as part of the cluster
I executed the following command to take the NIC offline on the worker node:
bootstrap $ ssh capv@<IP-ADD-RESS> capv@worker-node $ sudo ip link set eth0 down
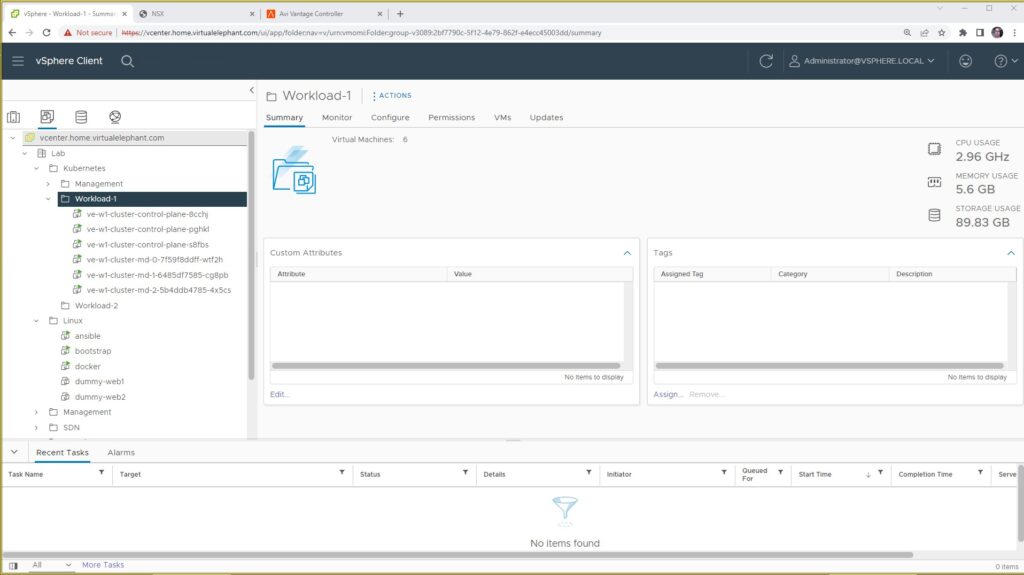
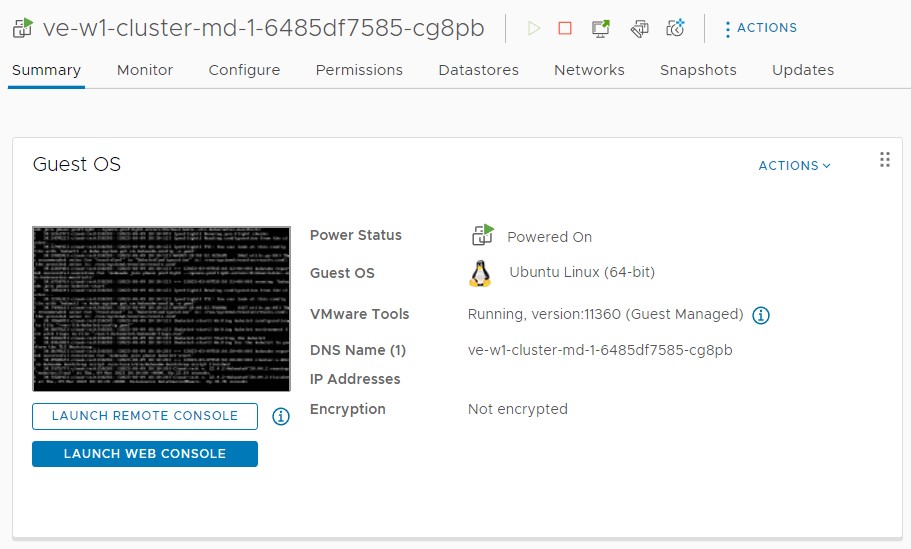
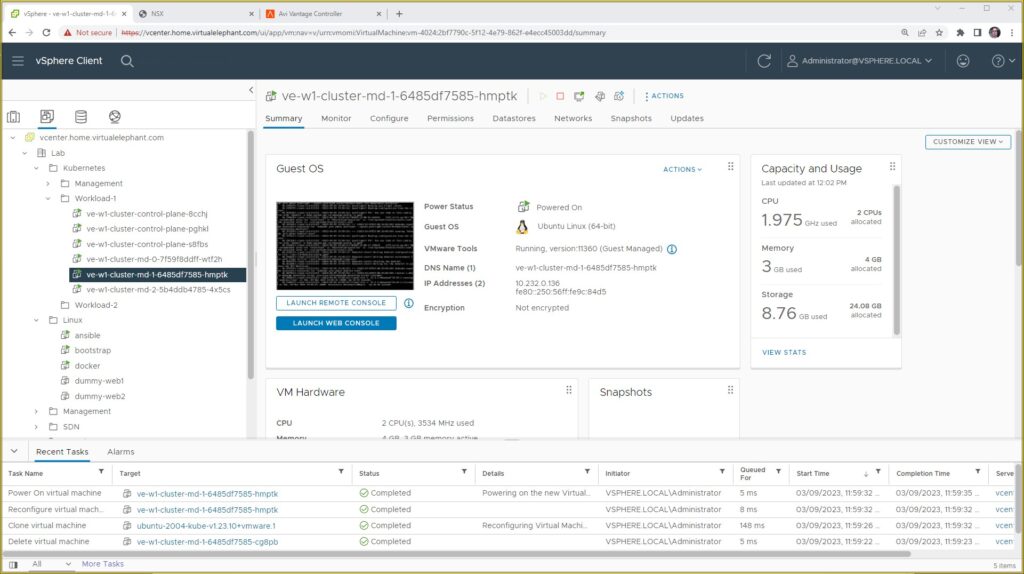
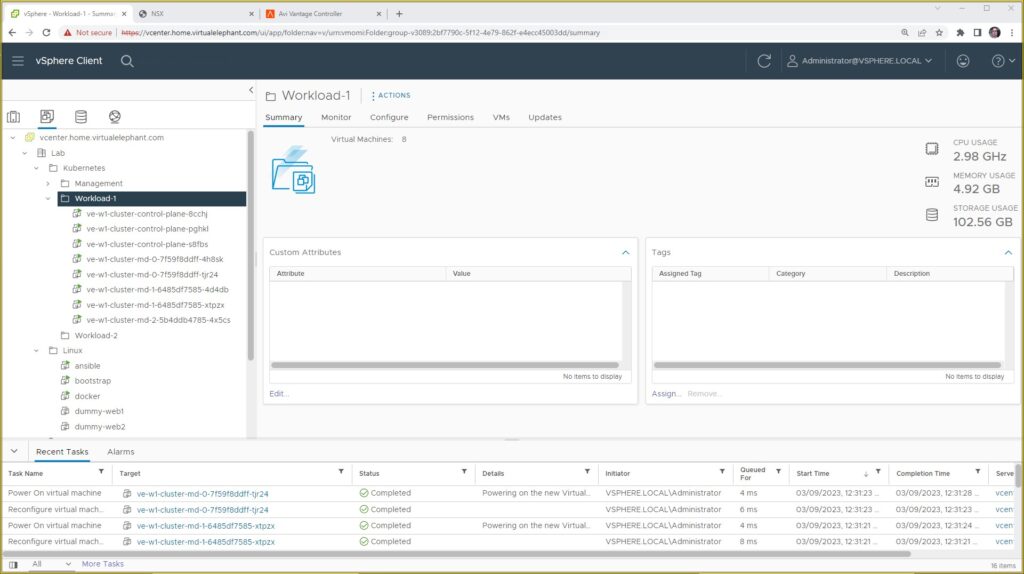
The screenshot below shows the VM inside vCenter Server and how it no longer has an IP address associated with it. The internal alert is captured every five minutes, at which time the TKG Management Cluster will initiate the workflow to bring a new worker node online.
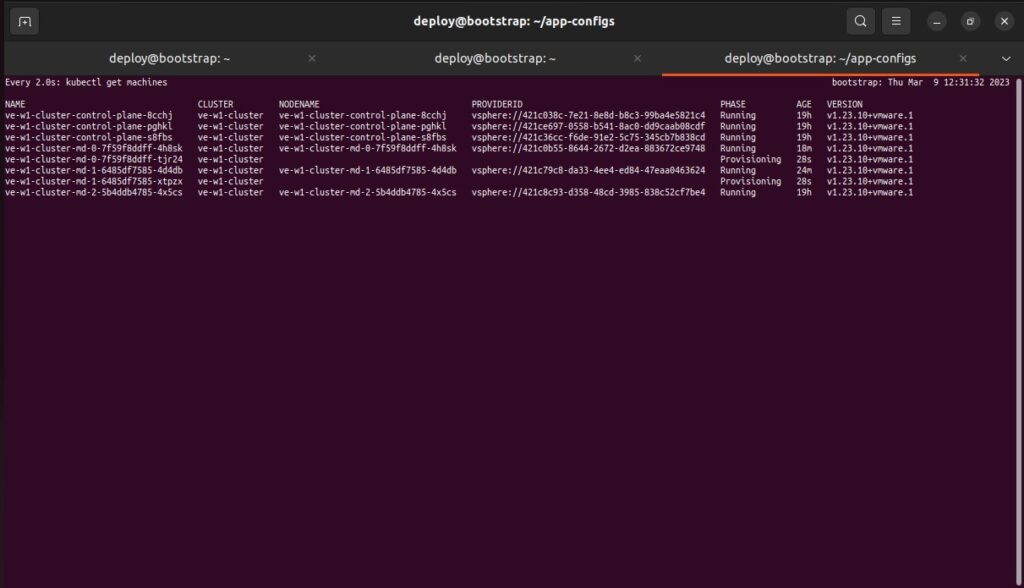
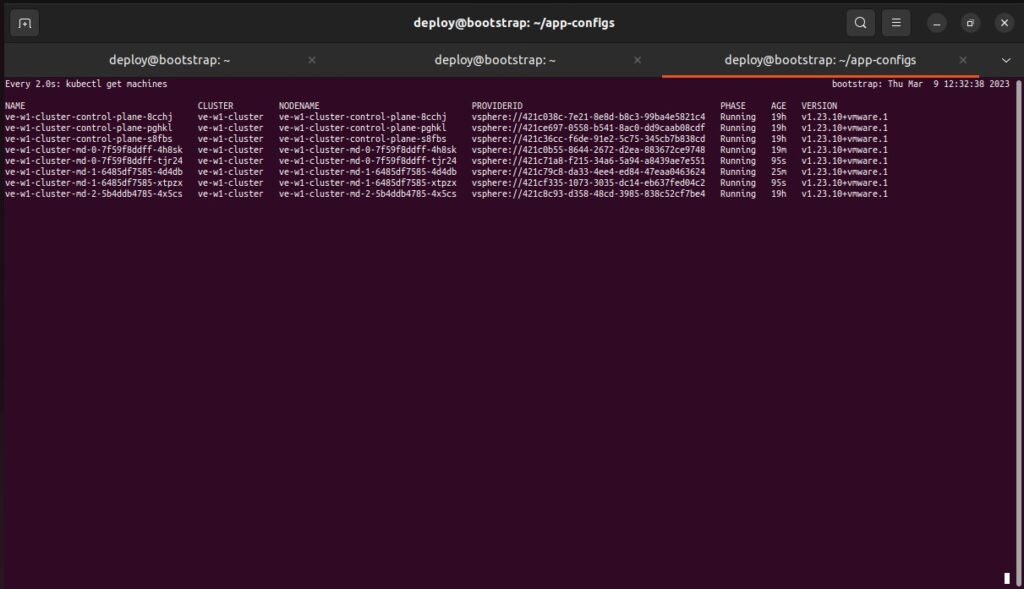
On the TKG Bootstrap VM, it is possible to monitor the machines and see when the workflow is initiated. Start by switching context over to the Management Cluster, and then run the command ‘watch kubectl get machines‘.
From a vCenter Server UI perspective, the screenshot below highlights the new VM the TKG Management Server created, along with the Recent Tasks where you can see the delete, clone, reconfigure, and power on actions that we performed. The full automation of Kubernetes nodes is seamless to end-users and administrators of the Tanzu Kubernetes Grid environment and is another advantage to running TKG within your VMware SDDC environment.
Kubernetes Cluster Scale Out
Tanzu Kubernetes Grid provides scaling of the Kubernetes clusters when an operator performs a set of commands within the Tanzu CLI. In addition, if the cluster deployment manifest enabled horizontal cluster autoscaling (for public cloud environments only), then clusters will automatically add or remove worker nodes based on CPU and memory utilization. The screenshots below demonstrate how a cluster can be scaled-out and scaled-in based on commands run on the Bootstrap VM against a specific TKG Workload Cluster.
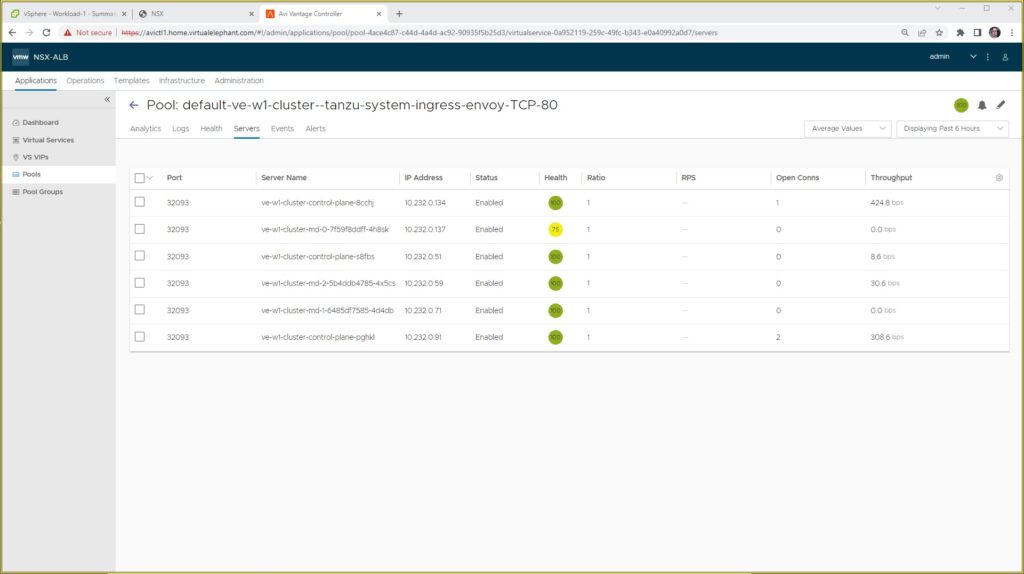
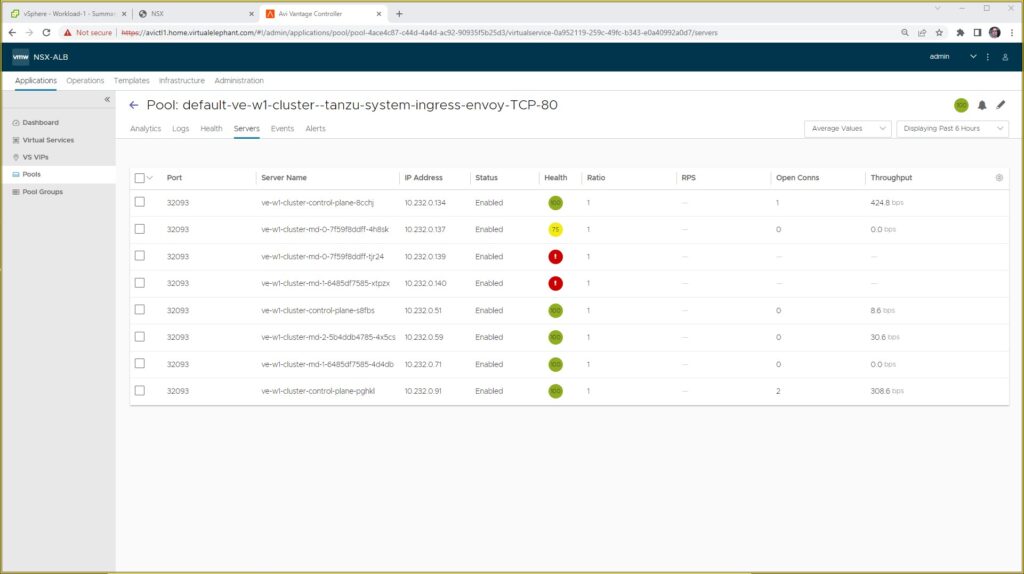
As we can see inside the NSX Advanced Load Balancer UI, the virtual service is currently setup to spread application traffic through all six of the Kubernetes nodes (3 control plane and 3 worker nodes).
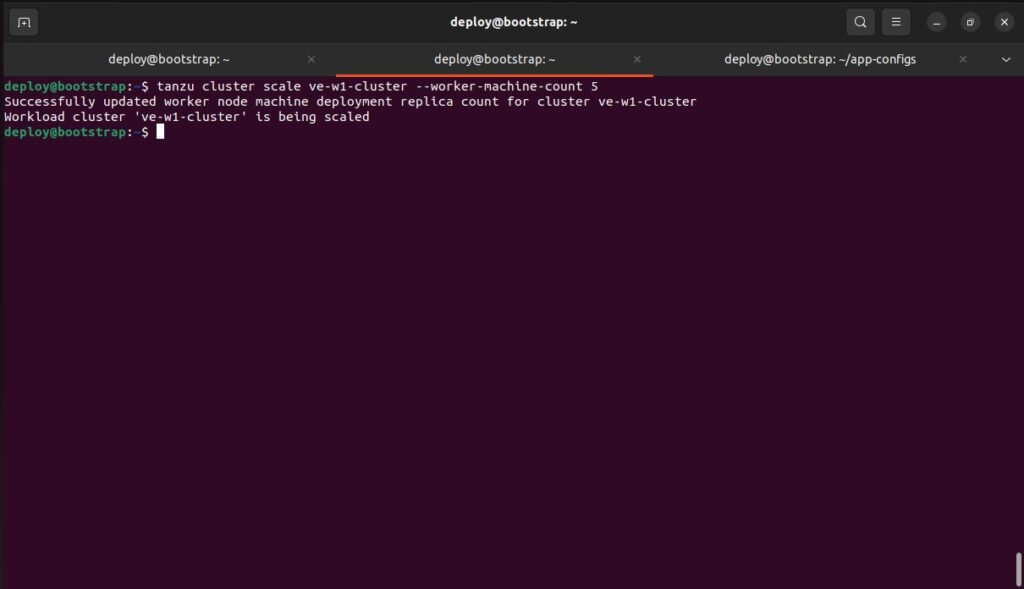
Performing a scale-out operation for the TKG Workload Cluster merely requires a single command to be executed on the Bootstrap VM.
bootstrap $ tanzu cluster scale <CLUSTER-NAME> --worker-machine-count X
A Kubernetes Administrator or Operator can monitor the progress of the scale-out operation through the TKG Management Cluster be executing the following command:
bootstrap $ watch kubectl get machines
As part of the scale-out operation, the NSX Advanced Load Balancer virtual service pool object is updated with the additional nodes created and added to the Kubernetes cluster.
Kubernetes Cluster Scale In
Tanzu Kubernetes Grid allows for the scale-in of the Kubernetes clusters as well. The workflow is similar to the scale-out process, only deleting existing objects rather than creating new ones. In order to scale-in a Kubernetes cluster managed by TKG, we use the same Tanzu CLI command, only with an integer smaller than the current number of deployed nodes.
bootstrap $ tanzu cluster scale <CLUSTER-NAME> --worker-machine-count Y
The workflow will delete X number of nodes to reduce the total number of worker nodes to match the integer Y. Just like the scale-out operation, the NSX Advanced Load Balancer objects will be updated to reflect these changes as well. No interaction is required by the Kubernetes Administrator or Operator.
Conclusion
Tanzu Kubernetes Grid enables automation around lifecycle activities common within a Kubernetes environment. The ability to dynamically scale a Kubernetes cluster and automatically failover onto new nodes when a node outage is encountered, drastically improves the day-to-day management for an IT Operations team.