

This is the third post in the Kubernetes with Cilium series that I am writing as I work towards running Kubernetes in my Home SDDC environment. The first two posts covered deploying a Kubernetes cluster with Cilium as the CNI, and deploying Hubble to visualize the relationships between containers deployed as a service within a Kubernetes cluster.
My purpose in writing these posts is threefold:
- Learn how Kubernetes works, both from an infrastructure and developer perspective.
- Compare and contrast many of the CNCF projects within the Kubernetes ecosystem.
- Share this information in a consumable format to others starting out.
As I’ve alluded to in the previous posts, my experience with the existing documentation to be challenging at times. Many blog articles, GitHub tutorials, official documentation assume the tools are being leveraged locally, either on a developers laptop or workstation — they do not seem to account for actual production use-cases where the Kubernetes cluster is running in a data center environment and being accessed remotely.
This post is going to focus on the challenges I have encountered thus far.
Persistent Volumes for Grafana
I quickly discovered the example deployment YAML file for Prometheus and Grafana to support Hubble did not maintain state when a container was restarted on a different node in the Kubernetes cluster. This is because the metrics were only being written locally to the container and that data was not available to the other nodes.
Persistent volumes are a pretty foundational part of Kubernetes, so this was a great opportunity to figure out how to start leveraging them within my environment. I decided to leverage an NFS server running on a VM outside of the Kubernetes cluster. I exported a single NFS share and mounted it on each node within the Kubernetes cluster.

I mounted the NFS share as /var/lib/grafana on each Kubernetes node and added an entry to the /etc/fstab file for each to make sure it was reconnected upon a reboot.
With the NFS share created and mounted, the only thing left was to get the grafana pod to leverage it when created inside the Kubernetes cluster. As noted in the previous post, I was leveraging the monitoring-example.yaml file that is available on the Cilium GitHub page. I made a local copy of the file on the master node and then proceeded to edit it with the following entries.

I specifically added lines 270-271 and 275-278. The Cilium Slack channel for Hubble was instrumental in helping out here and pointing me in the correct direction. From there, it was a matter of re-launching the pods inside the cilium-monitoring namespace — after first deleting the previous deployment.
$ kubectl delete -f https://raw.githubusercontent.com/cilium/cilium/v1.6/examples/kubernetes/addons/prometheus/monitoring-example.yaml $ kubectl apply -f monitoring-example.yaml
After validating the pod containers launched properly, I hopped over to the NFS server and verified data was being written to the persistent volume.

I proceeded to let Hubble run overnight, collecting metrics and then checked the UI in the morning and was happy to see everything was properly collecting data and visible to an operator.
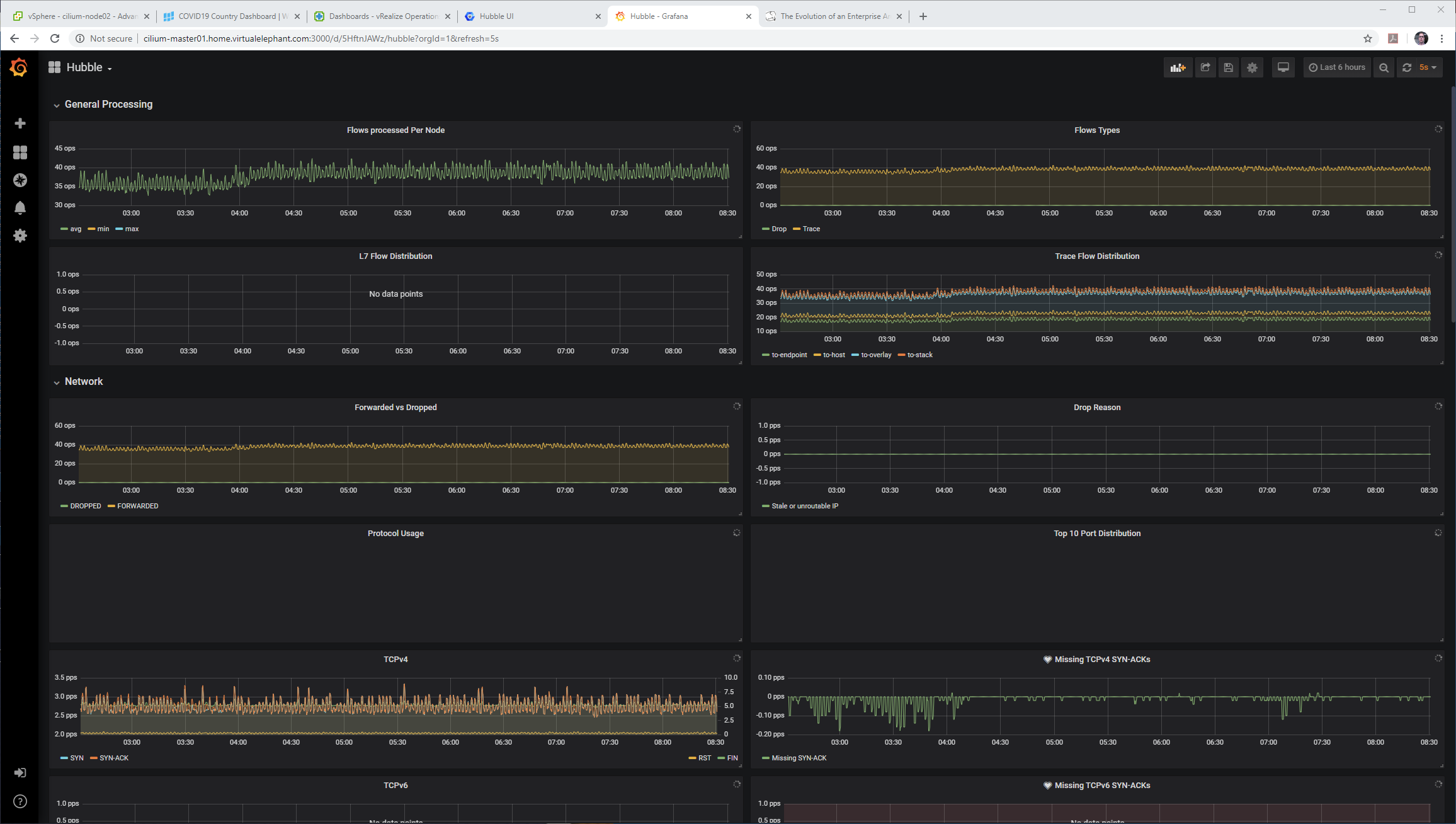
Hubble UI Errors
After having success with the persistent volume for the Grafana container, I left the port-forward open and after several hours began to see timeouts occurring in both the shell session and the brower.
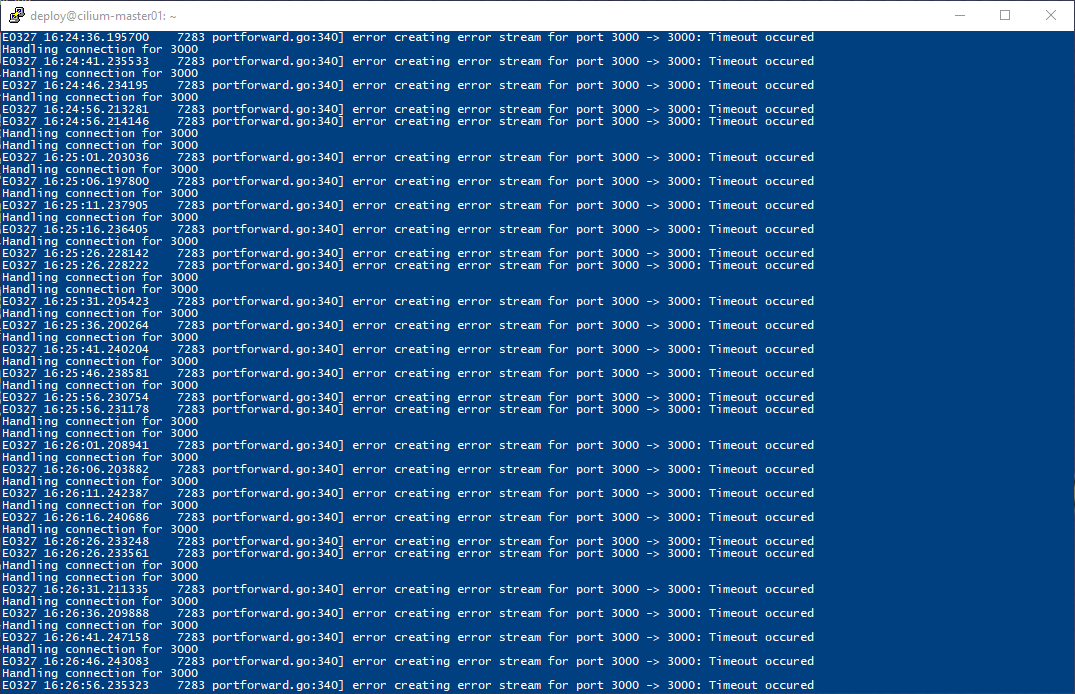
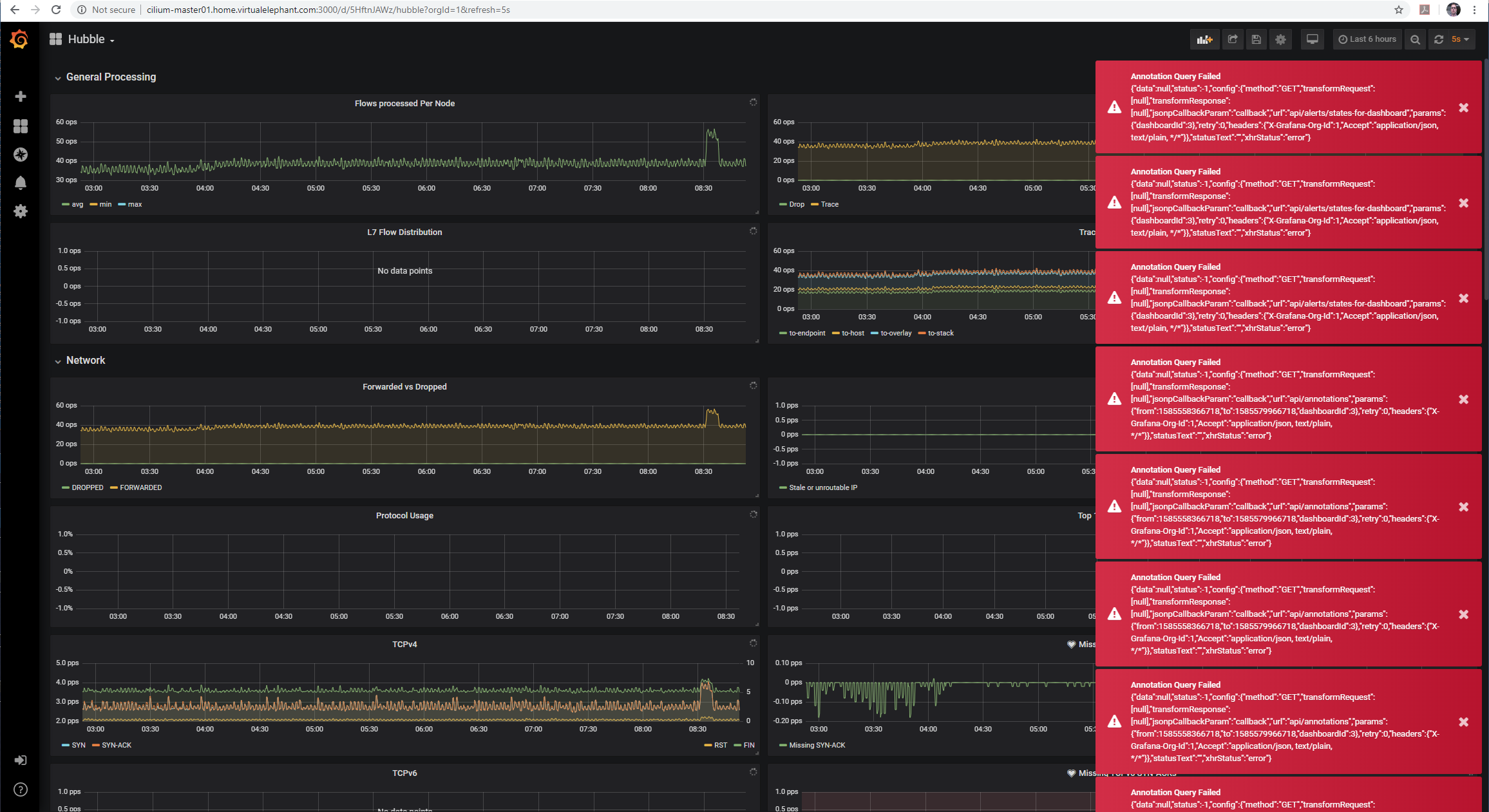
From there I went straight to my shell to check the status of the pods and what I found was several containers for Grafana and Prometheus in a terminating state, and that seemed to be stuck.
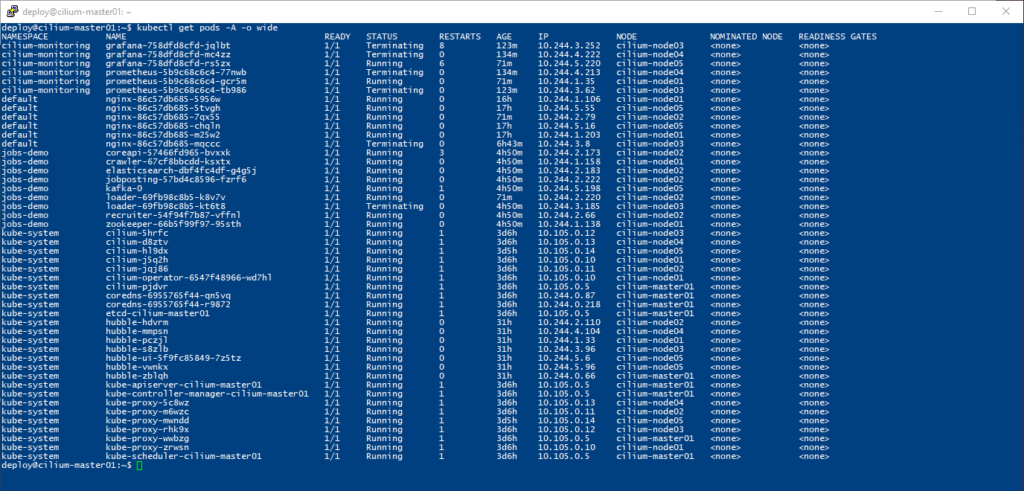
As I started to dive into the issue, I noted the cilium-node03 and cilium-node04 were showing high CPU and high memory usage — to the point that cilium-node03 would timeout when attempting to connect over SSH or the VM console.
After looking at the vRealize Operations graphs, I decided that the VMs needed to be scaled up to provide more resources to the nodes running Prometheus and Grafana.
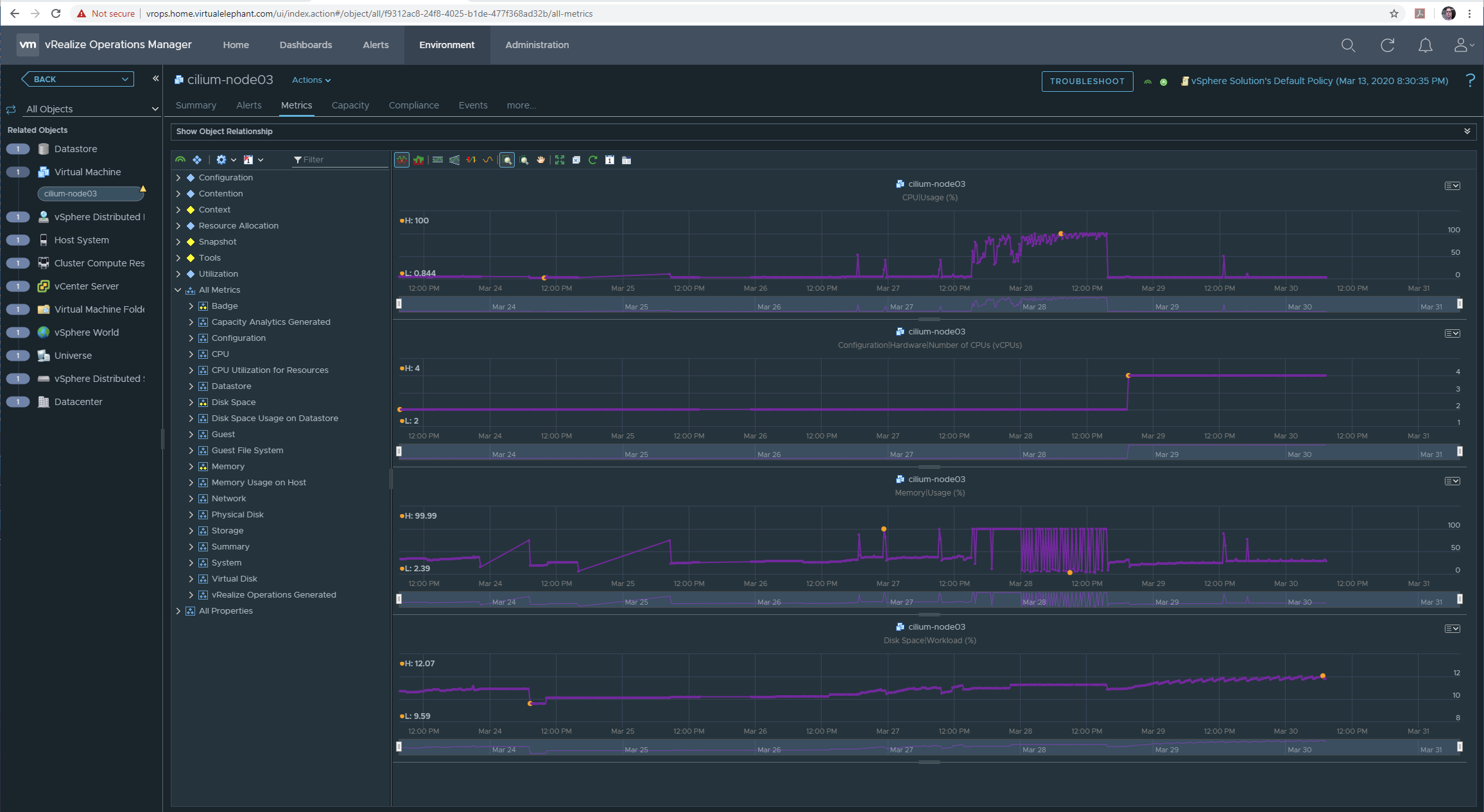
The new VM requirements for the entire cluster meant doubling the vCPU and memory for all the minion nodes. Each minion now has 4 vCPU and 8Gb of memory allocated to it. Since restarting each VM and increasing the resources, the port-forward timeout errors have disappeared.

Note the cilium-node03 minion where both Prometheus and Grafana are running are still consuming nearly all of the memory allocated to the VM. I tweeted about the memory issue on Sunday, so if you have any suggestions, please reach out.

In addition, the process of restarting each Kubernetes minion node allowed me to monitor the cluster status and all the pod services running in kube-system namespace as each node went offline and come back online. The overall process was rather clean and the cluster has been running smoothly ever since.
Conclusions
So far I feel rather successful in what I’ve been able to accomplish over the past couple of weeks with Kubernetes in my home SDDC environment. I still want to solve the challenge of having a port-forward open in a running shell in order to access the Hubble-UI and Grafana services. I’ve been reading on the ingress-nginx project and it looks promising, although I’m also wondering if a NSX-T load balancer would be an option too.
Reach out on Twitter if you have suggestions on how I can access Hubble-UI and Grafana without having a local shell open the entire time.
Enjoy!



