

Last year at VMworld, Andy and I spoke about the data pipeline and all of the different pieces involved and how their interactions lead to congestion. For any organization, how you deal with the data congestion will affect how much data an application can process. Fortunately, much like what Apache Hadoop has done for batch processing, Apache Storm has entered the real-time processing arena to help applications more efficiently process big data.
In case you are unfamiliar with Apache Storm, a basic explanation of its purpose and design can be seen on the Apache Storm site.
Storm is a distributed realtime computation system. Similar to how Hadoop provides a set of general primitives for doing batch processing, Storm provides a set of general primitives for doing realtime computation. Storm is simple, can be used with any programming language, is used by many companies, and is a lot of fun to use!
Hortonworks has provided some great insight into how Apache Storm can be utilized alongside Hadoop to allow organizations to become even more agile and efficient in their data pipeline processing. After hearing more and more about Apache Storm, I wanted to see if the architecture it employs would yield itself to being included in vSphere Big Data Extensions and a vSphere private cloud environment. Fortunately, the Apache Storm architecture has three clearly defined roles with easily understood relationships between each.
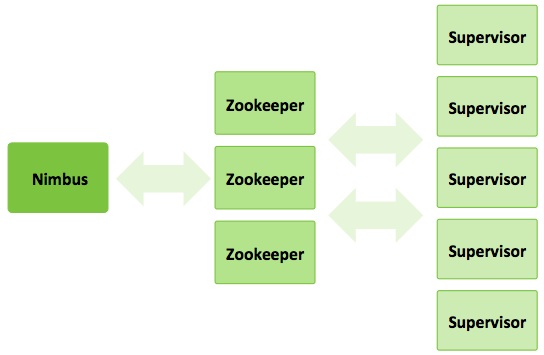
As the diagram shows, the three roles within Apache Storm include the Nimbus (master) node, Zookeeper nodes for managing the cluster and Supervisor (worker) nodes. Much like the work to include Apache Mesos, Marathon and Chronos within BDE, we are going to be defining new roles within Chef, creating a JSON specification file and developing Chef cookbooks for deploying each node type.
/opt/serengeti/www/specs/Ironfan/storm/spec.json:
1 {
2 "nodeGroups":[
3 {
4 "name": "Zookeeper",
5 "roles": [
6 "zookeeper"
7 ],
8 "groupType": "zookeeper",
9 "instanceNum": "[3,3,3]",
10 "instanceType": "[SMALL]",
11 "cpuNum": "[1,1,64]",
12 "memCapacityMB": "[7500,3748,min]",
13 "storage": {
14 "type": "[SHARED,LOCAL]",
15 "sizeGB": "[2,2,min]"
16 },
17 "haFlag": "on"
18 },
19 {
20 "name": "Nimbus",
21 "description": "The Storm master node",
22 "roles": [
23 "storm_nimbus"
24 ],
25 "groupType": "master",
26 "instanceNum": "[1,1,1]",
27 "instanceType": "[MEDIUM,SMALL,LARGE,EXTRA_LARGE]",
28 "cpuNum": "[1,1,64]",
29 "memCapacityMB": "[7500,3748,max]",
30 "storage": {
31 "type": "[SHARED,LOCAL]",
32 "sizeGB": "[1,1,min]"
33 },
34 "haFlag": "on"
35 },
36 {
37 "name": "Supervisor",
38 "description": "The Storm supervisor node",
39 "roles": [
40 "storm_supervisor"
41 ],
42 "instanceType": "[MEDIUM,SMALL,LARGE,EXTRA_LARGE]",
43 "groupType": "worker",
44 "instanceNum": "[3,1,max]",
45 "cpuNum": "[1,1,64]",
46 "memCapacityMB": "[7500,3748,max]",
47 "storage": {
48 "type": "[SHARED,LOCAL]",
49 "sizeGB": "[1,1,min]"
50 },
51 "haFlag": "off"
52 }
53 ]
54 }
Remember to create a new entry in the /opt/serengeti/www/specs/map file and the /opt/serengeti/www/distros/manifest file to account for the new cluster option.
The largest and most challenging part of adding functionality to the Big Data Extensions framework are the Chef recipes. I found several guides online that assisted me in determining how to deploy the Apache Storm software and supporting packages. I also prefer to use a series of cluster deployments to allow for trial and error while I work through the various pieces of configuration and package installation. Fortunately, the Chef server that is built into the Big Data Extensions management server allows you to test a node once it is online by re-running the chef-client command to deploy new code.
The source code for adding Apache Storm to the vSphere Big Data Extensions management server can be found within GitHub for Virtual Elephant.
The work continues to show engineering and operations teams the advantage of using vSphere Big Data Extensions for all types of next-generation or Platform 3 technologies to manage the SDLC from development through production.
If you have any questions on the work I’ve done to extend vSphere Big Data Extensions, please reach out to me on Twitter.
References
- Sipke, J. (2013, January 30). Installing a Storm cluster on CentOS hosts. Retrieved February 16, 2015, from http://jansipke.nl/installing-a-storm-cluster-on-centos-hosts/
- Hortonworks. (2014, July 2). Hortonworks Data Platform User Guides. Retrieved February 16, 2015, from http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1.3/bk_user-guide/bk_user-guide-20140702.pdf
- Setting up a Storm Cluster. (n.d.). Retrieved February 16, 2015, from https://storm.apache.org/documentation/Setting-up-a-Storm-cluster.html



