

Day 1 of the Adobe 2015 Tech Summit wrapped up a few hours ago and it was an outstanding day. Beyond the great speakers, they have provided a room filled with whiteboards on every surface — walls and tables — to allow groups of individuals to get together and brainstorm new ideas. I had the opportunity today to get together with several different architects and engineers to go over the work I have been doing — and documenting — here on Virtual Elephant over the past few months. I received some great feedback from several people which has fueled me further to continue running ahead to get these pieces all sorted out.
Currently today, I have a working lab environment where I can deploy everything from a persistent HDFS data warehouse layer, Mesosphere clusters, Apache Hadoop (compute-only) clusters and Apache Storm clusters through the VMware Big Data Extensions framework. From there, I have begun work on creating or using pre-existing Docker containers and loading them into the Mesosphere cell through the API. These containers are then able to access the persistent HDFS layer and write data down to be consumed by Hadoop clusters accessing the same layer.
The logical design looks like this:
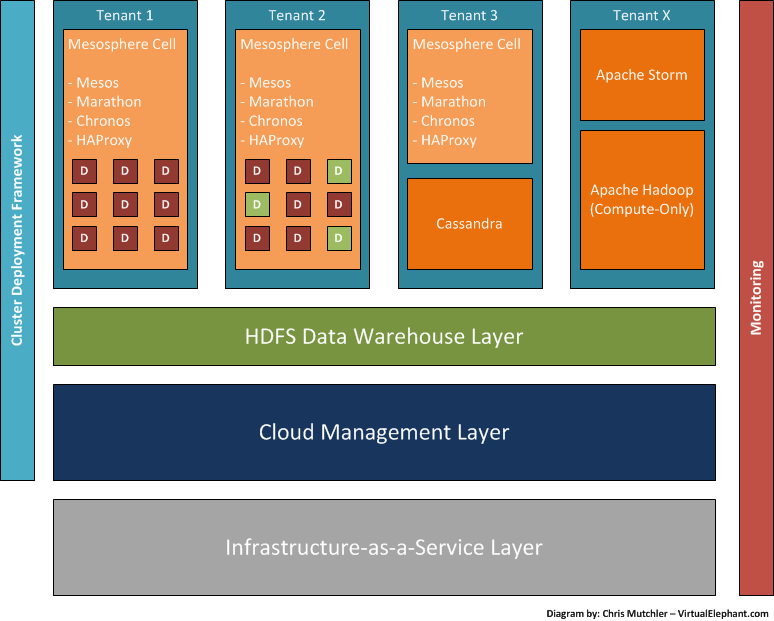
I have been focused on the layers above the Cloud Management Layer (CML) for the last six months, while my teammates have been focused on the CML layers down — specifically VIO, VSAN, NSX and vSphere. The best part of the journey has been the opportunity to see our efforts combining to create an end-to-end solution. In order to draw the focus away from the diagram, I have avoided calling out specific solutions for the CML, Monitoring and Cluster Deployment Framework. That being said, the work I have done with VMware Big Data Extensions has been leveraged in this work.
The interesting part that has come out of our combined efforts revolve around the capabilities of Heat templates and the JSON files that Big Data Extensions is leveraging today to define clusters. I tweeted about this briefly a bit ago and after having several good discussions, I believe the future roadmap for the work will be to add functionality to Big Data Extensions. I am hoping VMware will take the lead on this effort, as I firmly believe it will add great value to the product itself.



