

This is the first post in what I plan to be a sporadic, yet on-going series highlighting certain aspects of a VCDX / Architect skillset. These VCDX Quick Hits will cover a range of topics and key in on certain aspects of the VCDX blueprint. It is my hope they will trigger some level of critical thinking on the readers part and help them improve their skillset.
The idea for this post came after listening to a post-mortem call for a recent incident that occurred at work. The incident itself was a lower priority Severity 2 incident, meaning it only impacted a small subset of customers in a small failure domain (a single vCenter Server). As architects, we know monitoring is a key component of any architecture design — whether it is intended for a VCDX submission or not.
In IT Architect: Foundation in the Art of Infrastructure Design (Amazon link), the authors state:
“A good monitoring solution will identify key metrics of both the physical and virtual infrastructure across all key resources compute, storage, and networking.”
The post-mortem call got me thinking about maturity within our monitoring solutions and improving our architecture designs by striving to understand the components better earlier in the design and pilot phases.
It is common practice to identify the key components and services of an architecture we designed, or are responsible for, to outline which are key to support the service offering. When I wrote the VMware Integrated OpenStack design documentation, which later became the basis for my VCDX defense, I identified specific OpenStack services which needed to be monitored. The following screen capture shows how I captured the services within the documentation.
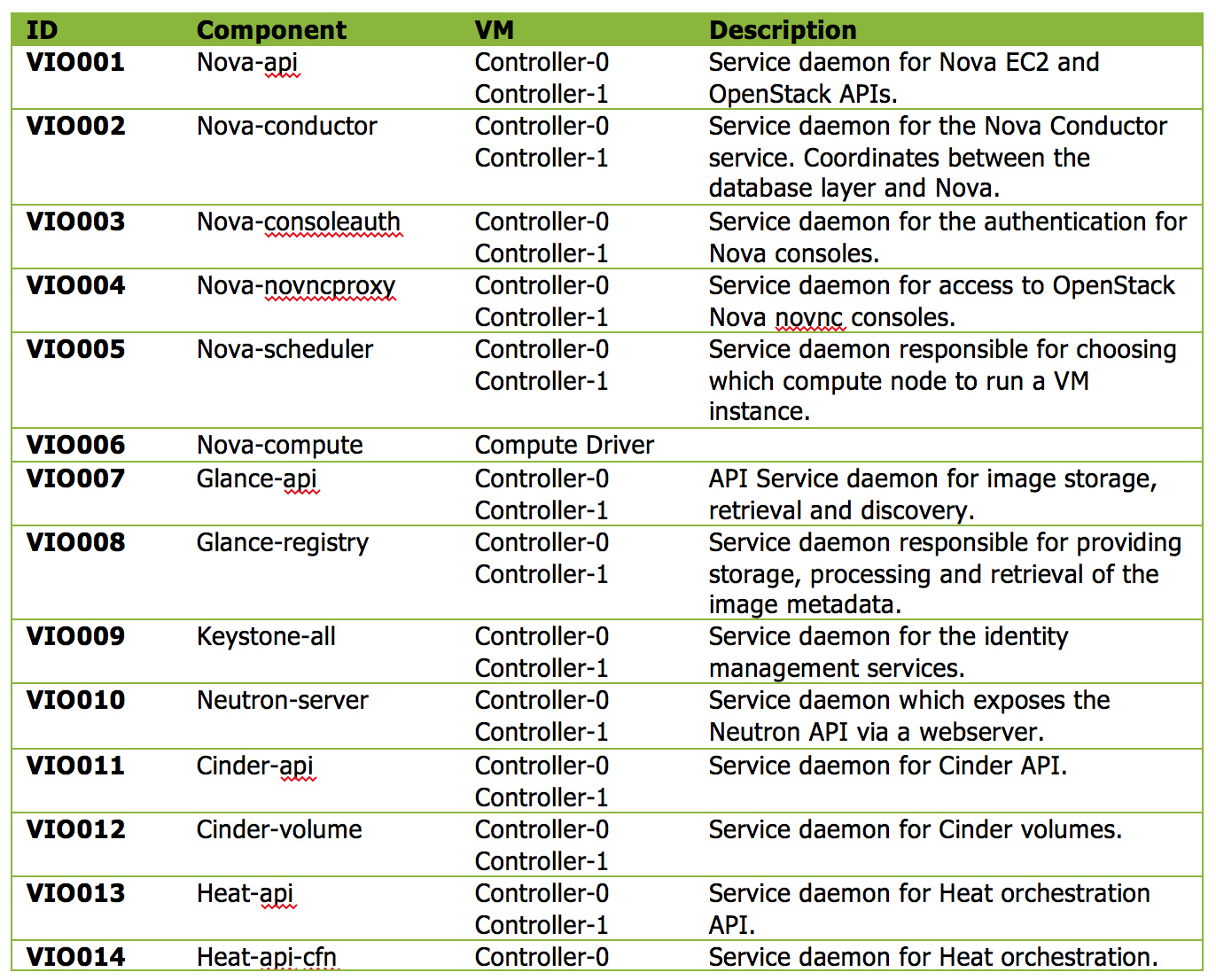
As you can see from the above graphic, I identified each service definition with a unique ID, documented the component/service, documented where the service should be running, and a brief description of the component/service. The information was used to create the Sprint story for the monitoring team to create the alert definitions within the monitoring solution.
All good right?
The short answer is, not really. What I provided in my design was adequate for an early service offering, but left room for further maturity. Going back to the post-mortem call, this is where additional maturity in the architecture design would have helped reduce the MTTR of the incident.
During the incident, two processes running on a single appliance were being monitored to determine if they were running. Just like my VMware Integrated OpenStack design, these services had been identified and were being monitored per the architecture specification. However, what was not documented was the dependency between the two processes. In this case, process B was dependent on process A and although process A was running, it was not properly responding to the queries from process B. As a result, the monitoring system believed everything was running correctly — it was from an alert definition perspective — and the incident was not discovered immediately. Once process A was restarted, it began responding to the queries from process B and service was restored.
So what could have been done?
First, the architecture design could have written an alert definition for the key services (or processes) that went beyond just measuring whether the service is running.
Second, the architecture design could have better understood the inter-dependencies between these two processes and written an more detailed alert definition. In this case, there was a log entry written each time process A did not correctly respond to process B. Having an alert definition for this entry in the logs would have allowed the monitoring system to generate an alert.
Third, the architecture design could have used canary testing as a way to provide a mature monitoring solution. It may be necessary to clarify what I mean when I use the term canary testing.
“Well into the 20th century, coal miners brought canaries into coal mines as an early-warning signal for toxic gases, primary carbon monoxide. The birds, being more sensitive, would become sick before the miners, who would then have a chance to escape or put on protective respirators.” (Wikipedia link)
Canary testing would them imply a method of checking the service for issues prior to a customer discovering them. Canary testing should include common platform operations a customer would typically do — this can also be thought of as end-to-end testing.
For example, a VMware Integrated OpenStack service offering with NSX would need to ensure that both the NSX Manager is online, but also that the OpenStack Neutron service is able to communicate to it. A good test could be to make an OpenStack Neutron API call to deploy a NSX Edge Service Gateway, or create a new tenant network (NSX logical switch).
There are likely numerous ways a customer will interact with your service offering and defining these additional tests within the architecture design itself are something I challenge you consider.



