

Everyone knows what an RTO is right?
When I ask this question during the VCDX Workshops, I inevitability get an answer along the lines of “Recovery Time Objective is how long it takes to recover an environment.” From a definition perspective, this is true — however, as with many concepts, especially as they relate to the VCDX certification, I believe there is more to it. When an organization defines an RTO target as part of a Business Continuity or Disaster Recovery plan, the architect responsible for delivering the platform to meet that target needs to understand what exactly the business requires.
When I worked in various operation teams, responsible for the data center infrastructure, a typical on-call escalation generally went like this.
- Alert is generated within a window 5-15 minutes of the service going offline.
- NOC / Tier 1 support team acknowledges the alert, determines which team is responsible for the alert.
- Depending on the organization, the NOC / Tier 1 team may attempt to triage the system prior to escalation.
- NOC / Tier 1 support team escalates to the Tier 2 team to further investigate the outage.
- Tier 2 team member may spend anywhere between 15 and 45 minutes investigating and/or attempting to resolve the outage.
- Tier 2 team member escalates issue to on-call or Tier 3 team.
- Tier 3 team investigates the issue, alerts or provides updates to the incident management team.
When I was on Tier 3 teams, participating in on-call responsibilities, by the time I was involved the outage had typically been ongoing anywhere from 30 minutes to 90 minutes — depending on the severity of the outage, level of investigation performed by Tier 1 and 2 teams, etc. This timeline is important as it relates to understanding the business requirements for executing a Business Continuity/Disaster Recovery (BCDR) plan, as it can or will immediately impact the ability to meet the target RTO.
As an architect, when we are gathering requirements from the stakeholders, we need to drill down into a realistic RTO target and understand all of the inter-dependencies for a BCDR plan.
I would argue in the example above, the timer for the RTO target shouldn’t begin when the alert is first generated, but rather when the business decides the issue is catastrophic enough to execute the BCDR plan and failover all of the identified services to a secondary location. If the business decides the timer should start when the first alert is generated, you will need to discuss operational plans and processes to assist the business in understanding how much time to allow for investigation prior to the decision to execute the BCDR plan.
Service Tier Inter-dependencies and the RTO
Similar to the service tier relationships and their impact on SLAs, the BCDR target RTOs are inter-related to one another. The key difference between the two inter-dependencies (SLO vs RTO) is that the RTOs are not linear, but rather interconnected. The following diagram illustrates the interconnectivity between the service tiers for RTOs.
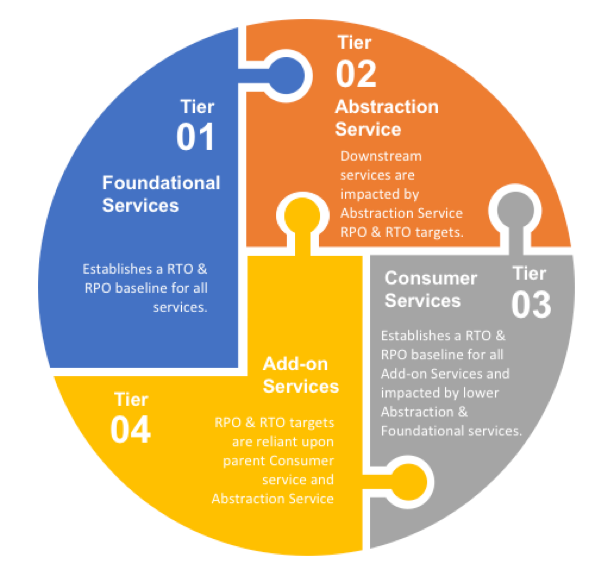
Depending on the type of service disruption or outage, a dependent service may be impacted by the lower-level services RTO and RPO targets.
In a region-wide failure, assuming all services will need to be restored in parallel, the recovery point and recovery time objectives will be equal to the maximum value of all the services.
From a VCDX certification perspective, it is important to be able to demonstrate your ability to understand and design around these interdependencies. I encourage all of us to further our understanding of the impact of our design choices to improve our skillset in the ever-evolving cloud technologies.



