

The final challenge in offering a full-featured Platform 3 private cloud utilizing OpenStack and VMware technologies has been the Platform-as-a-Service layer. VMware has many tools for helping individuals and companies offer a Platform-as-a-Service layer — vRealize Automation, vRealize Orchestrator and VMware Big Data Extensions. However, with the release of VMware Integrated OpenStack — and OpenStack in general — there is a disconnect between the Infrastructure-as-a-Service and Platform-as-a-Service layers. OpenStack has a few projects — like Sahara — to bridge the gap, but they are immature when compared to VMware Big Data Extensions. The challenge for me became figuring out a method for integrating the two so that an OpenStack offering built on top of VMware vSphere technologies could offer up a robust Platform-as-a-Service offering.
It has taken a fair bit of time, effort and testing, but I am pleased to announce the alpha release of the Virtual Elephant Big Data Extensions resource plugin for OpenStack Heat. The resource plugin enables an OpenStack deployment to utilize and deploy any cluster application the VMware Big Data Extensions management server is configured to deploy. The resource plugin accomplishes this by making REST API calls to the VMware Big Data Extensions management server to deploy the pre-defined JSON cluster specification files. The addition of the resource plugin to an OpenStack environment greatly expands the capabilities of the environment, without requiring a infrastructure engineer or architect to start from scratch.
The resource plugin itself requires several modifications to the VMware Big Data Extensions management server to be made. One challenge I encountered initially was lack of functionality built into the REST API. I received assistance from one of the VMware Big Data Extensions engineers — Jesse — who modified several of the JAVA jar files to add the features necessary. Writing the resource plugin would have been much more difficult were it not for several people at VMware — including Jesse, Andy and several of the VIO engineering team — who assisted me in my efforts. A big THANK YOU to each of them!
Disclaimer: As stated, the resource plugin is considered in an alpha state. It can be rather temperamental, but I wanted to get the code out there and (hopefully) get others excited for the possibilities.
Environment Notes
Obviously, there may be some differences between my OpenStack environment and your own. The work I have done has obviously been focused around VMware technologies, including Big Data Extensions. The other technologies the resource plugin relies upon are VMware Integrated OpenStack and VMware NSX. That is not to say the resource plugin will not work if you are using other OpenStack technologies, I mention it so that there is no misunderstanding the environment for which the plugin has been written.
Fortunately, the entire environment I designed the resource plugin for can be referenced on the OpenStack website, as it is the official reference architecture for VMware Integrated OpenStack the foundation has adopted.
http://www.openstack.org/enterprise/virtualization-integration
Final note before I begin discussing the installation and configuration required for the resource plugin — this level of modification of VMware Big Data Extensions will most likely put it into an unsupported state if you have issues and try to contact VMware support.
Installation Guide
In order to begin using the resource plugin, the VMware Big Data Extensions management server will need to be modified. Depending on how many of the additional cluster deployments you have integrated from the Virtual Elephant site, additional steps may be required to enable deployments of every cluster type. The resource plugin, REST API test scripts and the updated JAVA files can be downloaded from the Virtual Elephant GitHub site. Once you have checked-out the repository, perform the following steps within your environment.
Note: I am using VMware Integrated OpenStack and the paths reflect that environment. You may need to adjust the commands for your implementation.
Copy the resource plugin (BigDataExtensions.py) to the OpenStack controller(s): $ scp plugin/BigDataExtensions.py [email protected]:/usr/lib/heat $ ssh [email protected] "service heat-engine restart" $ ssh [email protected] "grep VirtualElephant /var/log/heat/heat-engine.log" $ scp plugin/BigDataExtensions.py [email protected]:/usr/lib/heat $ ssh [email protected] "service heat-engine restart" $ ssh [email protected] "grep VirtualElephant /var/log/heat/heat-engine.log" Copy the VIO config file (and modify) to the OpenStack controller(s): $ scp plugin/vio.config [email protected]:/usr/local/etc/ $ scp plugin/vio.config [email protected]:/usr/local/etc/ Copy the update JAVA files to the Big Data Extensions management server: $ scp java/cluster-mgmt-2.1.1.jar [email protected]:/opt/serengeti/tomcat6/webapps/serengeti/WEB-INF/lib/ $ scp java/commons-serengeti-2.1.1.jar [email protected]:/opt/serengeti/tomcat6/webapps/serengeti/WEB-INF/lib/ $ scp java/commons-serengeti-2.1.1.jar [email protected]:/opt/serengeti/cli/conf/ $ ssh [email protected] "service tomcat restart" If using VMware Integrated OpenStack, the curl package is required: $ ssh [email protected] "apt-get -y install curl" $ ssh [email protected] "apt-get -y install curl"
If you do not have a resource pool definition on the Big Data Extensions management server for the OpenStack compute cluster, you will need to create it now.
$ ssh [email protected] # java -jar /opt/serengeti/cli/serengeti-cli-2.1.1.jar serengeti> connect --host bde.localdomain:8443 serengeti> resourcepool list serengeti> resourcepool add --name openstackRP --vccluster VIO-CLUSTER-1
Note: If you use the resource pool name ‘openstackRP’, no further modifications to the JSON file are required. That value is the default for the resource plugin variable CLUSTER_RP, but it can be overridden in the JSON file.
At this point, the OpenStack controller(s) where Heat is running now have the resource plugin installed and you should have seen an entry stating it was registered when you restarted the heat-engine service. In addition, the management server for Big Data Extensions has the required updates that will allow the REST API to support the resource plugin. The next steps before the plugin can be consumed will be to copy/create JSON files for the cluster-types you intend to support within the environment. Within the GitHub repository, you will have an example JSON file that can be used. One of the updates to the management server included logic to look in the /opt/serengeti/conf file for these JSON files.
Copy example mesos-default-template-spec.json file: $ scp json/mesos-default-template-spec.json [email protected]:/opt/serengeti/conf/
Heat Template Configuration
When creating the JSON file (or YAML) for OpenStack Heat to consume, there are several key parameters that will be required. As this is the initial release of the resource plugin, there are additional changes planned for the future, including a text configuration file you will place on the controllers to hide several of these parameters.
Sample JSON entry with required parameters:
68 "Mesosphere-Tenant-0" : {
69 "Type" : "VirtualElephant::VMware::BDE",
70 "Properties" : {
71 "bde_endpoint" : "bde.localdomain",
72 "vcm_server" : "vcenter.localdomain",
73 "username" : "[email protected]",
74 "password" : "password",
75 "cluster_name" : "mesosphere_tenant_01",
76 "cluster_type" : "mesos",
77 "cluster_net" : { "Ref" : "mesos_network_01" }
78 }
79 }
You can see from the example above why parameters like ‘bde_endpoint’, ‘vcm_server’, ‘username’ and ‘password’ should be hidden by the consumers of the OpenStack Heat orchestration.
Once you have a JSON file defined, it can be deployed using OpenStack Heat — either through the user-interface or API. The deployment will then proceed and you can view the topology of the stack within your environment. If you use the JSON provided in GitHub (mesosphere_stack.json), it will look like the graphic below.
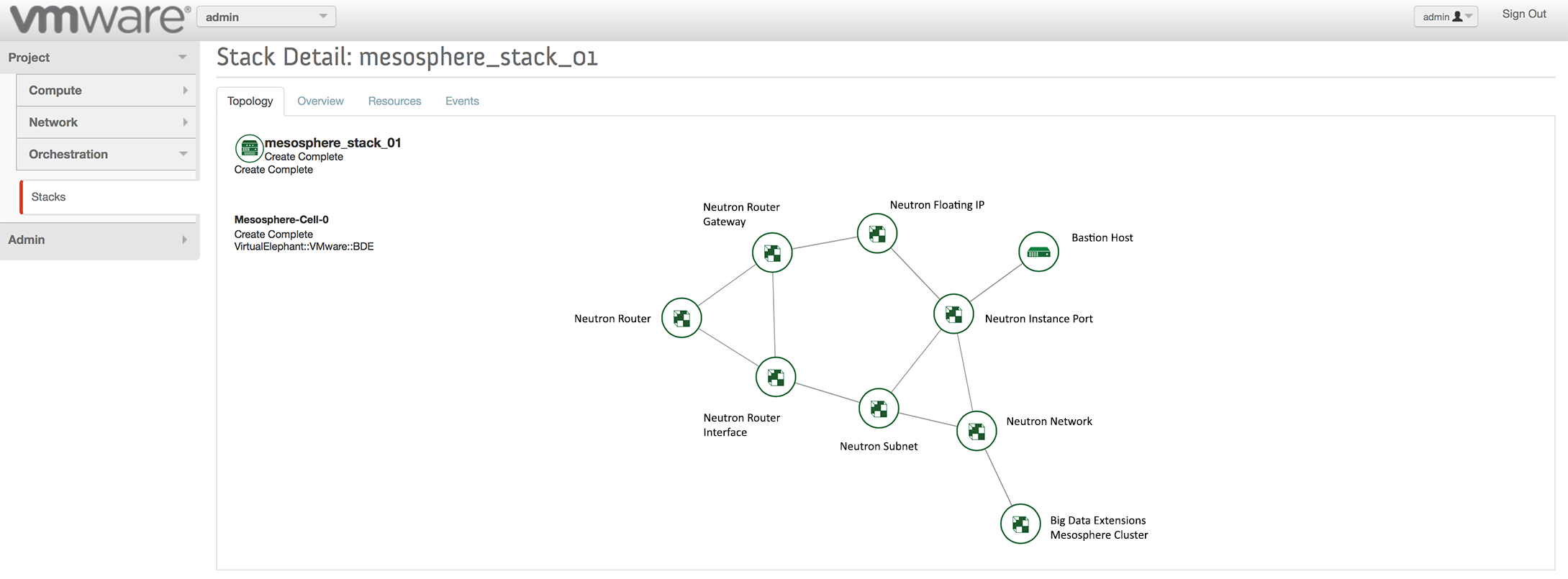
Congratulations — you have now extended your OpenStack environment to be able to support robust cluster deployments using the VMware Big Data Extensions framework!
Future Enhancements
The resource plugin is not yet fully-baked and there are several features I would still like to implement in the future. Currently, the resource plugin has the necessary code to deploy and delete clusters when initiated through OpenStack Heat. Features I will be working on extending in the future include:
- Report back to OpenStack cluster deployment status – currently a fire-and-forget mentality.
- Assign floating IP to the cluster.
- Ability to scale-out clusters deployed with OpenStack Heat.
- Enhance Big Data Extensions REST API to utilize JSON specification files in /opt/serengeti/www/specs/ versus the segregated JSON files it is using today.
- Support for prescribed VM template sizes (i.e. m1.small, m1.medium, m1.large, etc).
- Enhanced error detection for REST API calls made within the resource plugin.
- Cluster password support.
- Check and abide by Big Data Extensions naming-schema for cluster names.
- Incorporate OpenStack key-pairs with cluster nodes.
Closing Notes
There is always more work to be done on a project such as this, but I am excited to have the offering available at this time — even in its limited alpha state. Being able to bridge the gap between the Infrastructure-as-a-Service and Platform-as-a-Service layers is a key requirement for private cloud providers. The challenges I have faced (along with my coworkers) supporting our current environment and designing/implementing our next-generation private cloud have brought this reality to the forefront. In order to provide an AWS-like service offering, bridging the gap between the layers was an absolute necessity and I am extremely grateful for the support I have received from my peers in helping to solve this problem.
Look for an upcoming post going through the resource plugin code, highlighting the integration that was necessary between Big Data Extensions and NSX-v. In the meantime, reach out to me on Twitter (@chrismutchler) if you have questions or comments on the resource plugin, the OpenStack implementation or VMware Big Data Extensions.



